卷积神经网络
0x00 卷积神经网络(CNN)
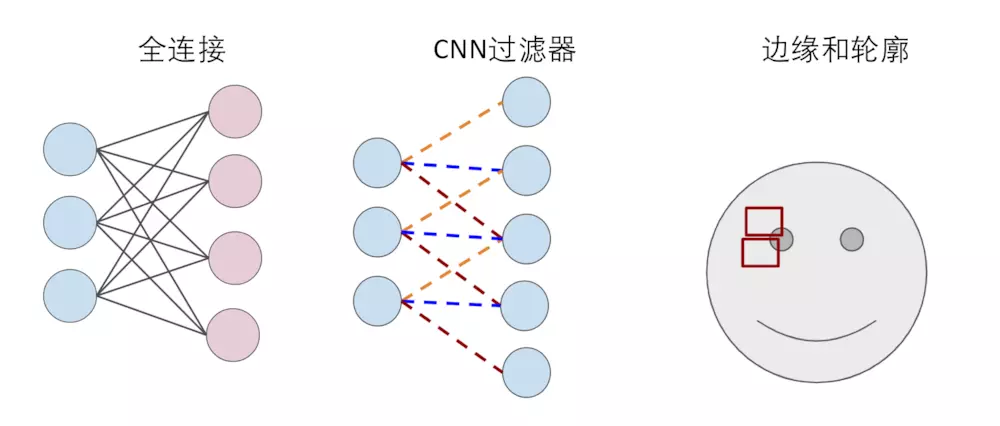
之前介绍的神经网络,每一层的每个神经元都与下一层的每个神经元相连,这种模式称之为全连接(Full Connected)。全连接意味着会产生大量的计算。在上面的例子中,我们可以看到如下代码:
1 | x = tf.placeholder(tf.float32, shape=[None, 784]) |
我们发现每一张图片中的784个像素点都与下一层的神经元进行了计算。这种全连接的方法用在图像识别上明显太笨了,因为我们识别MNIST中的数字的话,我们只需要识别数字的轮廓即可,而如何找到数字的轮廓只与当前像素点与其周围的像素点有关。
这个时候卷积神经网络(CNN)就派上用场了,卷积神经网络可以简单地理解为,用滤波器(Filter)将相邻像素之间的轮廓过滤出来,如图:
下面我们来详细描述一下卷积的过程。首先我们来看如下动图:
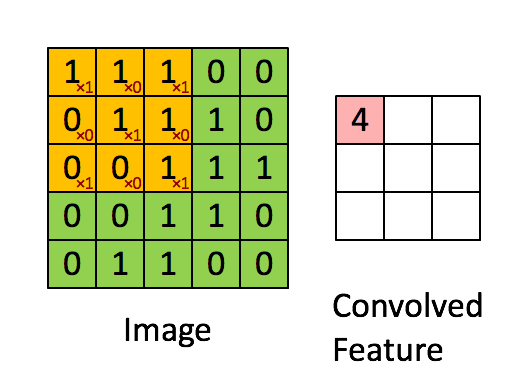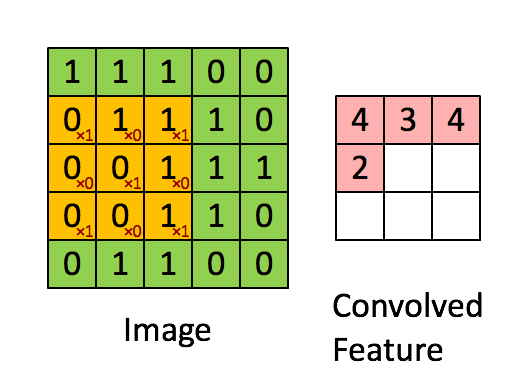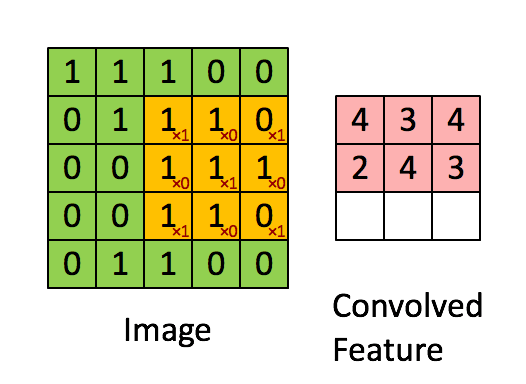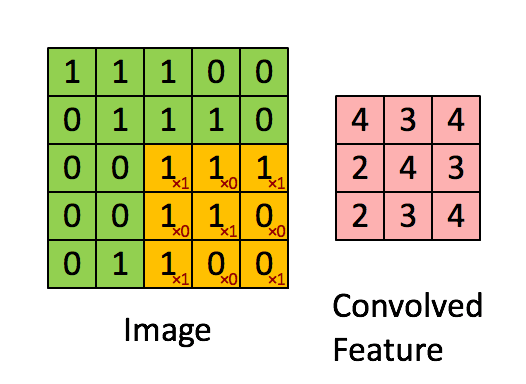
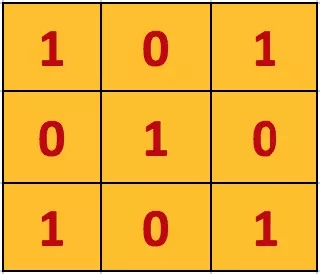
图中有一个黄色的小方块,那个即称为卷积核,他实际的形状实则为一个矩阵:
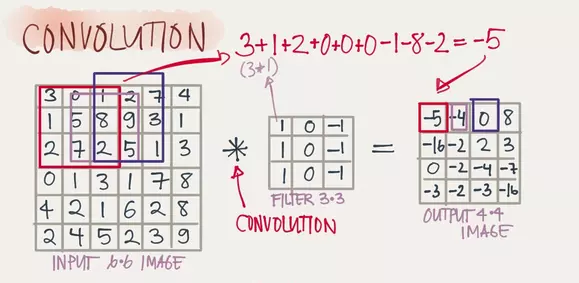
在卷积核走过的过程中,卷积核与覆盖图像的部分进行计算然后得到卷积特征矩阵中某个元素的值,计算方式为卷积核与其覆盖图像的部分每个元素进行乘积然后逐个相加得到最终卷积矩阵元素。如图:
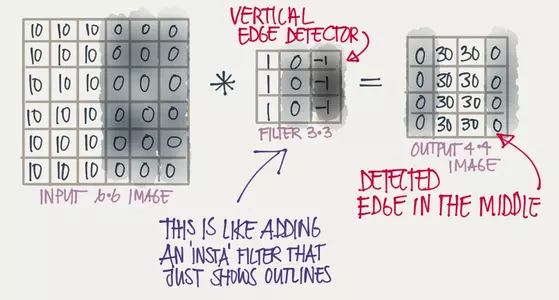
这样做的意义在于可以清晰地划分出图像轮廓,例如在下图中,原矩阵在中间有一条明显的竖直轮廓,轮廓左边是10右边是0,在通过一个3x3的矩阵卷积后得到的结果中,这条轮廓被明显地表示出来了:
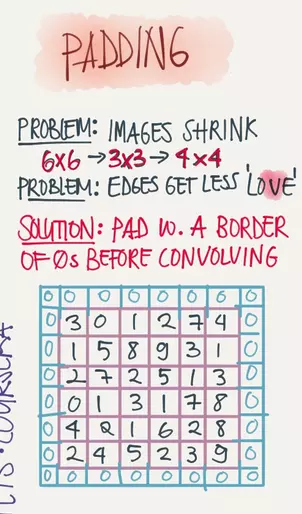
在上面的例子中,一个6x6的输入矩阵在3x3的卷积矩阵的作用下得到的结果是一个4x4的矩阵,如果我们想让结果矩阵和输入矩阵一般大,那我们就需要用到填充(Padding),一般我们使用的方法为SAME Padding,即为在原矩阵外面包裹一层0,如下:
我们再来回顾一下刚才这幅动图:
通过一步步地移动卷积的窗口来完成卷积操作,每次移动的步长即成为stride,步长和padding的大小共同决定了输出层图像的大小。
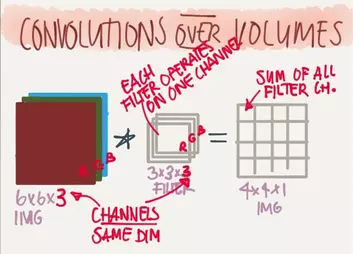
当我们对彩色的训练图片进行处理的时候,所有的色彩都可以由RGB三原色组成,因此我们对彩色图片使用卷积神经网络训练时,往往使用三个通道来对每个颜色进行过滤。于是一个长宽各为6个像素的彩色图片,可以表示为一个6x6x3的3D物体,然后我们使用3x3x3(最后一个3代表通道数)来进行卷积,卷积后将3个通道内的元素相加将其最终合并为1张输出层图片,由此我们将得到一个4x4x1的输出层图片。此时输出层的深度(depth)即为1。如图:
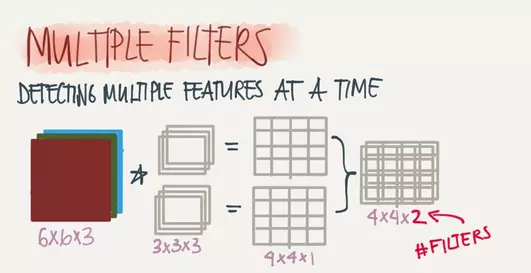
增加卷积核的个数即可增加输出层图片的个数,例如下图中一个6x6x3的输入层图片在2个3x3x3的卷积核的作用下可以得到两个4x4x1的输出层图片。
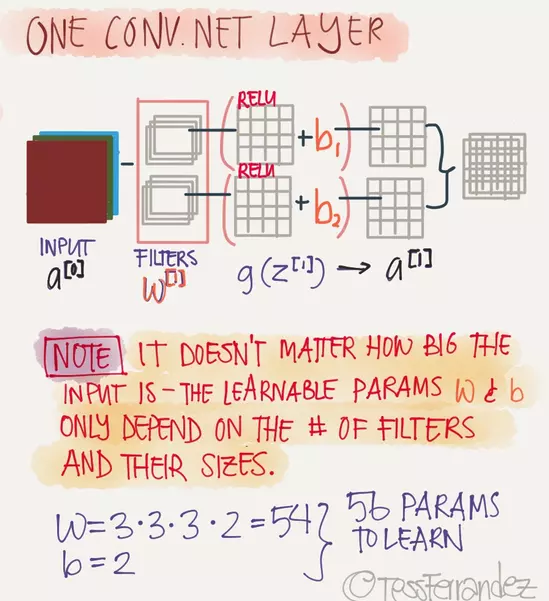
之前我们所创造的全连接神经网络,通常需要一个线性函数()和一个激活函数共同作用,CNN也是如此,通常在滤波器之后还要加一个激活函数(在图像识别中一般使用Relu函数),CNN中的线性函数同样需要一个权重项W以及一个偏置项b,在CNN中一般使用滤波器的数值作为W,偏置项b一般加在Relu函数之后。如下图所示:
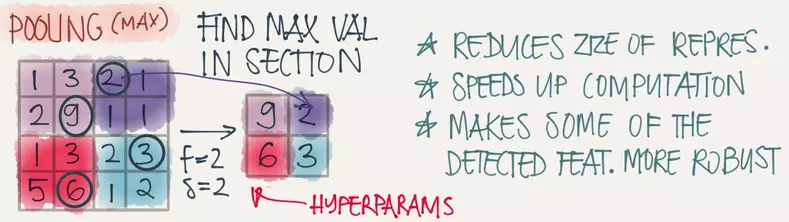
卷积层后面就是池化(pooling)层,池化层主要用于特征降维、压缩数据和参数的数量、加快卷积的速度、减少过拟合,同时提升模型的容错性。池化的方法有很多种,最常用的为max-pooling,即取一个区域的最大值,如图即为将一个4x4的图片max-pooling成一个2x2的图片:
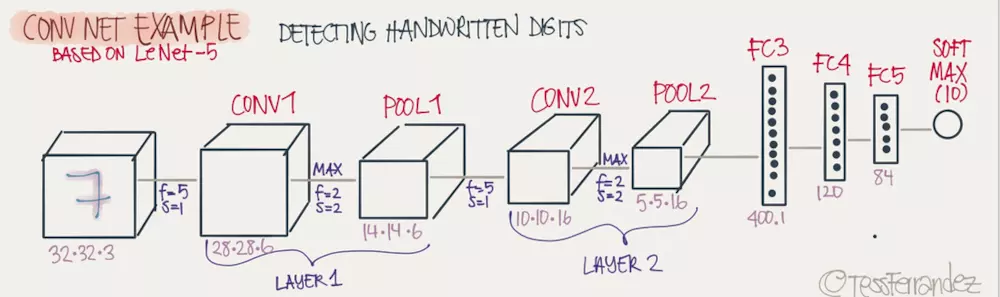
由此,我们有了一个完整的卷积神经网络,其通常有一个或多个的卷积层加池化层,最后再附上几个完整层(Full Connected)构成,如图所示:
0x01 使用CNN训练MNIST
1 | import tensorflow as tf |
最终测试结果,训练集准确率99.89%,测试集准确率99.11%。
 支付宝
支付宝- 微信


