Caffe 初上手
0x00 Caffe的安装
Caffe的安装是非常费劲的,我在曾花了2天时间查阅了无数的资料修改了无数的错误才在win 10上使用Visual Studio成功编译了一个GPU版本的Caffe,所以极其不建议大家自己编译安装Caffe,建议使用docker,GPU版本请使用nvidia-docker。nvidia-docker的安装可以参考其GitHub上的描述,还是非常轻松的。这是Caffe在docker hub上的镜像仓库:
1 | https://hub.docker.com/r/bvlc/caffe |
最新版本的nvidia-docker已经停用了nvidia-docker这个命令,取而代之的是docker run --gpus,通过参数--gpus来指定启用GPU支持和具体连接哪一块GPU,一般后面跟参数all用来指定连接所有的GPU。
当然,你也可以使用device参数来指定连接某一块具体的GPU:
1 | docker run -it --rm --gpus device=GPU-3a23c669-1f69-c64e-cf85-44e9b07e7a2a ubuntu nvidia-smi |
如下,我们使用docker来启动一份Caffe镜像:
1 | docker run --gpus all -it bvlc/caffe:gpu bash |
该命令使用后,我们即可得到一份镜像内的终端,使用如下命令,即可查看Caffe是否已经正确加载GPU:
1 | root@444e9951d54b:/workspace# caffe device_query -gpu 0 |
通过上述命令返回结果,我们已经看到其已经正常加载GPU,我们就可以使用其来训练神经网络啦。
我们要使用docker来加载Caffe训练一个神经网络,首先我们需要做的,就是把外部的训练数据和与训练相关的网络信息和配置文件传入docker容器内,我们可以使用docker的文件映射功能,将物理机中的文件夹映射至docker容器中,参考如下命令:
1 | docker run --gpus all -it -v /media/ubuntu/mnist:/workspace --name caffe bvlc/caffe:gpu bash |
在上述命令中,我们使用-v将物理机中的/media/ubuntu/mnist映射到docker容器中的/workspace目录下,这样在docker容器中对/workspace目录的访问就相当于对物理机中/media/ubuntu/mnist的访问了。这个访问是双向的,我们可以将caffe在docker容器中的训练结果保存到容器的/workspace目录下,这样我们就可以在物理机中的/media/ubuntu/mnist拿到相关的结果。同样,我们也可以将相关的测试数据放入物理机中的/media/ubuntu/mnist目录下,这样我们就可以在容器中指定/workspace为相关的数据和网络参数路径。
TL;DR
如果上述的流程在你的电脑上训练模型时出现如下错误的话:
这是由于你的显卡配置错误导致的,这个配置是在
$CAFFE_ROOT下的Makefile.config里面配置的,重新配置需要重新编译caffe,重新编译以修正此错误可以参考如下文章:caffe深度学习【十八】Check failed: error == cudaSuccess (8 vs. 0) invalid device function
如果你在docker里面运行出现了上述的错误,那就不建议你修改
Makefile.config然后重新编译了,这个可以通过换docker镜像直接解决,我们上面所用的docker镜像是bvlc/caffe:gpu,我们只要换成NVIDIA caffe(NVCaffe)即可:
主页:nvidia/caffe
P.S.
上述镜像可以直接从docker hub中获取,但是已经被标记为弃用(DEPRECATED)了。我们可以从NVIDIA GPU Cloud中下到最新版本,但是因为国内众所周知的网络原因,下面的命令往往不能正常地拉取镜像,需要给docker配置代理才能正常拉取:
主页:NVCaffe
0x01 获取MNIST数据集并转换为LMDB格式
MNIST数据集有一套自己的格式封装,而我们要使用Caffe进行训练需要将其转换为LMDB格式,Caffe的example里面已经为我们提供了相关的转换脚本,我们直接调用即可:
1 | cd $CAFFE_ROOT |
0x02 输入层
我们接下来来好好看一下这个神经网络,我们先来看其输入层:
1 | layer { |
transform_param用于对输入数据进行一些变换,scale用于对其中的像素值进行缩放,将其值投射到区间[0, 1)中,其值为。这一层产生2个blob,一个是data一个是label。data_param中的batch_size指的是一次从数据集中读取的数据量的大小。
我们定义了训练和测试两个阶段的2个输入层,分别从两个不同的路径读取训练数据和测试数据。
top用于指定该层的输出,我们由此看到该层的输出有2,其一为data,也就是数据,其二为label,也就是其所对应的标签。
0x03 卷积层
1 | layer { |
卷积层的type为Convolution,对于参数lr_mult意指对基础学习率的系数,也就是实际学习率为在solver文件里面指定的基础学习率base_lr乘以这里的lr_mult。对于当前layer里面指定的第一个param其针对训练参数w,第二个param其对应训练参数b,由此我们可以看出,在上述的例子中,当前层对b的学习率是对w的学习率的两倍,且对w的学习率等同于其在solver.prototxt文件中指定的基础学习率。
对于convolution_param,其用于指定一些关于卷积核的参数。num_output为卷积的通道数,换句话说也就是卷积核的个数。kernel_size为卷积核的大小,在这里指定一个5,意为卷积核的大小为5x5。stride用于指定卷积核行走时的步长。weight_filler即为使用何种算法来填充卷积核,在这里指定的是xavier算法。bias_filler即为填充b矩阵的填充方法,在这里指定的为constant,使用常量(一般为0)填充。
TL;DR
卷积流程:
2
3
4
5
6
7
8
9
10
# shape中的第一个-1用于表示输入图片的数量,如同x shape中的None
# 28, 28, 1用于表示这是一个28x28的图片,有1个通道(因为都是黑白的)
x_image = tf.reshape(x, shape=[-1, 28, 28, 1])
# 卷积核的宽度和高度均为4,第一层输入通道数为1,输出通道数为32
# 将一张图片分为32个特征
con1_weight = init_weight([4, 4, 1, 32])
con1_bias = init_bias([32])
con1 = tf.nn.relu(conv2d(x_image, con1_weight) + con1_bias)
下面又引出来了一个bottom和一个top,用于指定该层的输入参数和输出参数。其实在我看来,Caffe中的bottom和top后面只不过是起到了一个标签的作用,在输入层中我们定义了两个top,一个是data一个是label,data和label实则为用于标记数据的标签,然后在卷积层中的bottom指定为data,告诉Caffe该层需要获取一个标签值为data的数据。然后Caffe会自动将带有这个标签的数据作为输入传入该层。
0x04 池化层
1 | layer { |
池化层的type为Pooling,使用pooling_param为其设置相关参数,其内部的pool参数用于指定池化的方法,在这采用的是最常用的max-pooling,也就是取一个区域内的最大值,如下图所示:
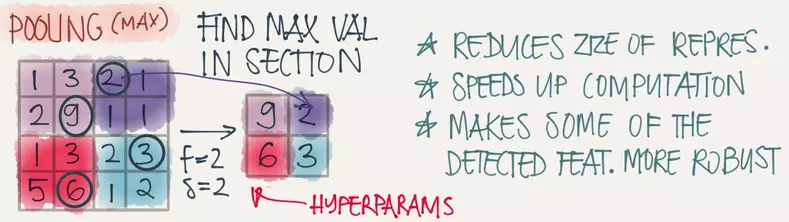
kernel_size用于指定max-pooling的区域大小,在这的设定为2,也就是2x2。stride用于指定池化的步长为2,这样池化的过程中就不会出现重叠的情况了。这跟上图所示是一样的情况。
0x05 全连接层和激活函数层
1 | layer { |
全连接层里面所有的参数,在上面基本上都已经讲过了,下面着重说说中间那个激活函数层。
因为激活函数的计算是可以就地(in-place)计算的,所以我们就可以有如下的设置:
1 | bottom: "ip1" |
就是该层的输入和输出都是在一个标签所标记的数据上完成的。如果top不等于bottom的话,就会把计算好的输出数据放在一个新建的名为你新指定的名称的数据集中。
0x06 误差层和精度测算层
1 | layer { |
softmax是一个激活函数,softmax返回一个概率矩阵,即预测的one-hot集中每一个数据的概率。误差层不会带有任何输出,但是会将预测结果与正确结果作为此层的输入。该层主要用于计算误差,然后将其用于反向传播的过程之中。
0x07 Solver
1 | # The train/test net protocol buffer definition |
 支付宝
支付宝- 微信


