0x00 线性单元
上节所讲的感知器在实际应用中存在一个问题,即当处理的数据集不是线性可分的时候,其可能面临着无法收敛的问题,无法收敛就意味着我们可能永远无法完成一个感知器的训练。为了解决这个问题,我们使用一个可导的线性函数来代替感知器的阶跃函数。这种感知器即称为线性单元。当线性单元遇到数据不可分的情况时,会收敛到一个最佳的近似上。
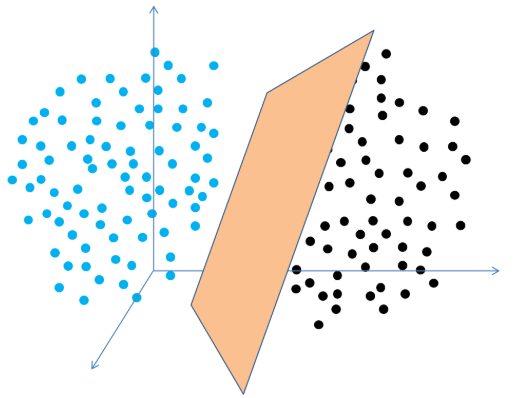
线性可分
概念:可以用一个线性函数把两类样本分开
在二维空间中,要分开两个线性可分的点集合,我们需要找到一条分类直线:
在三维空间中,我们需要找到一个分类面:
0x01 线性模型的表示
我们实际上在做的工作就是通过输入值x来预测输出值y。比方说输入你午饭吃掉的食品种类及克数计算你所摄入的卡路里的数量。假设说我们午饭吃掉了米饭200克、西瓜100克、肉制品50克的话。我们可以将每种食品的食用量都看做一个输入特征,由此就可以使用一个向量来表示我们的输入,这个向量即称为特征向量,如下:
x = [ 200 100 50 ] x=\left[
\begin{matrix}
200\\ 100\\ 50
\end{matrix}
\right]
x = 200 100 50
此后,因为每克不同的食物所包含的卡路里的数量也不尽相同,所以我们还需要引入一个权值矩阵,假设每克米饭含有1单位的卡路里、西瓜0.5单位、肉制品1.5单位,则我们的权值矩阵如下:
W = [ 1 0.5 1.5 ] W=\left[
\begin{matrix}
1&0.5&1.5
\end{matrix}
\right]
W = [ 1 0.5 1.5 ]
此时,我们这顿饭所摄入的卡路里总量就可以表示为如下的形式:
h ( x ) = W x = [ 1 0.5 1.5 ] [ 200 100 50 ] = 1 × 200 + 0.5 × 100 + 1.5 × 50 h(x)=Wx=\left[
\begin{matrix}
1&0.5&1.5
\end{matrix}
\right]\left[
\begin{matrix}
200\\100\\50
\end{matrix}
\right]
=1\times200+0.5\times100+1.5\times50
h ( x ) = W x = [ 1 0.5 1.5 ] 200 100 50 = 1 × 200 + 0.5 × 100 + 1.5 × 50
这就是我们的线性模型,输出h(x)是所有输入特征x的线性组合。
0x02 梯度下降
在使用监督学习的方法训练时,通过一个输入样本x,经过假设函数h(x)的计算得到一个预测值y ˉ \bar{y} y ˉ x i x_i x i
e ( i ) = 1 2 ( y ( i ) − y ˉ ( i ) ) 2 e^{(i)}=\frac{1}{2}(y^{(i)}-\bar{y}^{(i)})^2
e ( i ) = 2 1 ( y ( i ) − y ˉ ( i ) ) 2
一个训练集中可以有多个样本,比如N个,由此,我们可以把全部样本的误差值累加,得到所有样本的误差和,由此来评估样本总体的误差,如下:
E = e ( 1 ) + e ( 2 ) + ⋯ + e ( n ) = 1 2 ∑ i = 1 n ( y ( i ) − y ˉ ( i ) ) 2 \begin{align*}
E&=e^{(1)}+e^{(2)}+\cdots+e^{(n)} \\
&=\frac{1}{2}\sum_{i=1}^{n}(y^{(i)}-\bar{y}^{(i)})^2
\end{align*}
E = e ( 1 ) + e ( 2 ) + ⋯ + e ( n ) = 2 1 i = 1 ∑ n ( y ( i ) − y ˉ ( i ) ) 2
我们将假设函数h(x)带入上式,可有:
E = 1 2 ∑ i = 1 n ( y ( i ) − w x ( i ) ) 2 E=\frac{1}{2}\sum_{i=1}^{n}(y^{(i)}-wx^{(i)})^2
E = 2 1 i = 1 ∑ n ( y ( i ) − w x ( i ) ) 2
我们训练模型的目的就是让这个误差函数的值尽可能地小,在上式中x ( i ) , y ( i ) x^{(i)}, y^{(i)} x ( i ) , y ( i )
我们都知道,函数的极值点即为其导数等于0的点。在计算函数f(x)的极小值时,我们可以通过求解方程f ′ ( x ) = 0 f'(x)=0 f ′ ( x ) = 0
梯度是一个向量,指向函数数值上升最快的方向,显然梯度的反方向就是下降最快的方向。我们每次沿着梯度的反方向去修改x的值,每次修改的大小即称为步长,步长太大,可能我们一下子就越过了那个最小值的位置,步长太小,就会耗时很长时间经过多轮迭代才能抵达最小值。由此我们可以写出梯度下降的公式:
x new = x old − η ∇ f ( x ) x_{\text{new}}=x_{\text{old}}-\eta\nabla{f(x)}
x new = x old − η ∇ f ( x )
其中,∇ \nabla ∇ η \eta η
w new = w old − η ∇ E ( w ) \mathrm{w}_{\text{new}}=\mathrm{w}_{\text{old}}-\eta\nabla{E(\mathrm{w})}
w new = w old − η ∇ E ( w )
其中:
∇ E ( w ) = ∂ E ( w ) ∂ w \nabla{E(\mathrm{w})}=\frac{\partial E(\mathrm{w})}{\partial\mathrm{w}}
∇ E ( w ) = ∂ w ∂ E ( w )
经过一番复杂的数学变换,我们把这个偏导数求出来了,结果值为:
∇ E ( w ) = − ∑ i = 1 n ( y ( i ) − y ˉ ( i ) ) x ( i ) \nabla{E(\mathrm{w})}=-\sum_{i=1}^{n}(y^{(i)}-\bar{y}^{(i)})x^{(i)}
∇ E ( w ) = − i = 1 ∑ n ( y ( i ) − y ˉ ( i ) ) x ( i )
代入得:
w new = w old + η ∑ i = 1 n ( y ( i ) − y ˉ ( i ) ) x ( i ) \mathrm{w}_{\text{new}}=\mathrm{w}_{\text{old}}+\eta\sum_{i=1}^{n}(y^{(i)}-\bar{y}^{(i)})x^{(i)}
w new = w old + η i = 1 ∑ n ( y ( i ) − y ˉ ( i ) ) x ( i )
如果我们根据上式来训练样本,那么每更新一次w都会遍历训练数据中所有的样本进行计算。当我们的样本数据量非常大的时候,这同样会产生极大的计算量,由此我们引入了随机梯度下降算法(SGD)。在SGD中,每次更新w只计算一个样本,因为样本的噪音性和随机性,所以SGD在进行每次更新的时候并不一定都是向着E减小的方向,然而,虽然存在一定的随机性,但整体上还是好的,而且最后也能将值收敛到最小值附近。下图展示了SGD和BGD的区别,粉红色线表示SGD,可以明显看出SGD虽然历经曲折,但是整体大方向还是向着最小值的地方靠拢的。
在上面我们写明白了预测权重矩阵W的方法,对于一个线性函数来说,形式往往是y = w x + b y=wx+b y = w x + b
对于偏差值b,我们可以将其看成一个特殊的w,只不过这个特殊的w对应的输入值x永远为1就是了,这样就可以把这个多出来的b转化为一个永远乘以1的w 0 w_0 w 0
h ( x ) = W x + b = [ w 1 w 2 w 3 ] [ x 1 x 2 x 3 ] + b = w 1 x 1 + w 2 x 2 + w 3 x 3 + b = w 1 x 1 + w 2 x 2 + w 3 x 3 + w 0 × 1 \begin{align*}
h(x)=Wx+b=&\left[
\begin{matrix}
w_1&w_2&w_3
\end{matrix}
\right]\left[
\begin{matrix}
x_1\\ x_2\\ x_3
\end{matrix}
\right]+b\\
=& w_1x_1+w_2x_2+w_3x_3+b \\
=& w_1x_1+w_2x_2+w_3x_3+w_0\times 1
\end{align*}
h ( x ) = W x + b = = = [ w 1 w 2 w 3 ] x 1 x 2 x 3 + b w 1 x 1 + w 2 x 2 + w 3 x 3 + b w 1 x 1 + w 2 x 2 + w 3 x 3 + w 0 × 1
乃至,我们可以将输入数据扩展一行,权值矩阵W扩展一列,将b转移到矩阵W内:
h ( x ) = W x + b = w 1 x 1 + w 2 x 2 + w 3 x 3 + b = w 1 x 1 + w 2 x 2 + w 3 x 3 + w 0 × 1 = [ w 1 w 2 w 3 b ] [ x 1 x 2 x 3 1 ] \begin{align*}
h(x)=Wx+b=& w_1x_1+w_2x_2+w_3x_3+b \\
=& w_1x_1+w_2x_2+w_3x_3+w_0\times 1 \\
=& \left[
\begin{matrix}
w_1&w_2&w_3&b
\end{matrix}
\right]\left[
\begin{matrix}
x_1\\ x_2\\ x_3\\ 1
\end{matrix}
\right]
\end{align*}
h ( x ) = W x + b = = = w 1 x 1 + w 2 x 2 + w 3 x 3 + b w 1 x 1 + w 2 x 2 + w 3 x 3 + w 0 × 1 [ w 1 w 2 w 3 b ] x 1 x 2 x 3 1
由此,我们就可以用上面所讲的方法,用训练w的方法来训练b了。
0x03 手写线性拟合
下面的代码,我们使用了上述处理偏置值b的第一种方法,将其看成一个特殊的w项,然后使用等同于w项的处理方法来进行训练,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 import numpy as npclass LinearFittingPredictor : def __init__ (self, learn_rate ): self.w = 0 self.b = 0 self.learn_rate = learn_rate def get_prediction (self, input_x ): return self.w * input_x + self.b def train (self, train_x, train_y, iter ): for _ in range (iter ): self.w = self._train_w(train_x, train_y, self.w) self.b = self._train_b(train_x, train_y, self.b) def _nabla_E_w (self, train_x, train_y ): sum = 0 for i in range (0 , len (train_x)): sum = sum + (train_y[i] - self.get_prediction(train_x[i])) * train_x[i] return -sum def _nabla_E_b (self, train_x, train_y ): sum = 0 for i in range (0 , len (train_x)): sum = sum + (train_y[i] - self.get_prediction(train_x[i])) * 1 return -sum def _train_w (self, train_x, train_y, w_old ): return w_old - self.learn_rate * self._nabla_E_w(train_x, train_y) def _train_b (self, train_x, train_y, b_old ): return b_old - self.learn_rate * self._nabla_E_b(train_x, train_y) x = np.random.rand(1000 , 1 ) y = 10.21 * x + 12.11 predictor = LinearFittingPredictor(0.001 ) predictor.train(x, y, 100 ) print (predictor.w)print (predictor.b)
训练的结果值为:
1 2 [10.20978574] [12.11010666]
这个值已经很接近我们预设的w(10.21)和b(12.11)的值了。
同样,如上面所讲,我们也可以将偏置值b作为一个x恒为1的特殊的w,来进行处理,如下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import numpy as npclass LinearFittingPredictor : def __init__ (self, learn_rate ): self.w = np.array([0 , 0 ]) self.learn_rate = learn_rate def get_prediction (self, input_x ): input_x = np.append(input_x, 1 ).reshape(2 , 1 ) return self.w.dot(input_x) def train (self, train_x, train_y, iter ): for _ in range (iter ): self._train_w(train_x, train_y) def _nabla_E_w (self, train_x, train_y ): sum = 0 for i in range (0 , len (train_x)): x_i = np.array([train_x[i][0 ], 1 ]) sum = sum + (train_y[i][0 ] - self.get_prediction(train_x[i][0 ])) * x_i return -sum def _train_w (self, train_x, train_y ): self.w = self.w - self.learn_rate * self._nabla_E_w(train_x, train_y) x = np.random.rand(1000 , 1 ) y = 10.21 * x + 12.11 predictor = LinearFittingPredictor(0.001 ) predictor.train(x, y, 120 ) print (predictor.w)
上述代码训练所产生的结果如下:
1 [10.20911554 12.11048001]
0x04 下面的你可以当没看见
这是我脑子里面想了,然后随便写的一部分内容,写完了又不舍得删于是就留在这里了。没有阅读的必要哦!
首先我们先引入上面所写的误差函数E:
E = e ( 1 ) + e ( 2 ) + ⋯ + e ( n ) = 1 2 ∑ i = 1 n ( y ( i ) − y ˉ ( i ) ) 2 \begin{align*}
E&=e^{(1)}+e^{(2)}+\cdots+e^{(n)} \\
&=\frac{1}{2}\sum_{i=1}^{n}(y^{(i)}-\bar{y}^{(i)})^2
\end{align*}
E = e ( 1 ) + e ( 2 ) + ⋯ + e ( n ) = 2 1 i = 1 ∑ n ( y ( i ) − y ˉ ( i ) ) 2
拟合曲线的话,我们的y ˉ \bar{y} y ˉ
y ˉ = tanh ( w x + b ) \bar{y}=\tanh(wx+b)
y ˉ = tanh ( w x + b )
依据梯度下降的公式我们可以有:
w new = w old − η ∇ E ( w ) \mathrm{w}_{\text{new}}=\mathrm{w}_{\text{old}}-\eta\nabla{E(\mathrm{w})}
w new = w old − η ∇ E ( w )
此后:
∇ E ( w ) = ∂ E ( w ) ∂ w = ∂ ∂ w ( 1 2 ∑ i = 1 n ( y ( i ) − y ˉ ( i ) ) 2 ) = ∂ ∂ w ( 1 2 ∑ i = 1 n ( y ( i ) − tanh ( w x ( i ) + b ) ) 2 ) = − ∑ i = 1 n ( y ( i ) − tanh ( w x ( i ) + b ) ) × tanh ′ ( w x ( i ) + b ) × x ( i ) = − ∑ i = 1 n ( y ( i ) − y ˉ ( i ) ) × tanh ′ ( w x ( i ) + b ) × x ( i ) \begin{align*}
\nabla{E(\mathrm{w})}&=\frac{\partial E(\mathrm{w})}{\partial\mathrm{w}}\\
&=\frac{\partial}{\partial\mathrm{w}}\left(\frac{1}{2}\sum_{i=1}^{n}(y^{(i)}-\bar{y}^{(i)})^2\right)\\
&=\frac{\partial}{\partial\mathrm{w}}\left(\frac{1}{2}\sum_{i=1}^{n}(y^{(i)}-\tanh(w x^{(i)}+b))^2\right)\\
&=-\sum_{i=1}^{n}(y^{(i)}-\tanh(w x^{(i)}+b))\times \tanh'(w x^{(i)}+b)\times x^{(i)}\\
&=-\sum_{i=1}^{n}(y^{(i)}-\bar{y}^{(i)})\times \tanh'(w x^{(i)}+b)\times x^{(i)}
\end{align*}
∇ E ( w ) = ∂ w ∂ E ( w ) = ∂ w ∂ ( 2 1 i = 1 ∑ n ( y ( i ) − y ˉ ( i ) ) 2 ) = ∂ w ∂ ( 2 1 i = 1 ∑ n ( y ( i ) − tanh ( w x ( i ) + b ) ) 2 ) = − i = 1 ∑ n ( y ( i ) − tanh ( w x ( i ) + b )) × tanh ′ ( w x ( i ) + b ) × x ( i ) = − i = 1 ∑ n ( y ( i ) − y ˉ ( i ) ) × tanh ′ ( w x ( i ) + b ) × x ( i )
由基础数学知识可知:
tanh ′ ( x ) = 1 − tanh 2 ( x ) \tanh'(x)=1-\tanh^2(x)
tanh ′ ( x ) = 1 − tanh 2 ( x )
代入∇ E ( w ) \nabla{E(\mathrm{w})} ∇ E ( w )
∇ E ( w ) = − ∑ i = 1 n ( y ( i ) − y ˉ ( i ) ) × tanh ′ ( w x ( i ) + b ) × x ( i ) = − ∑ i = 1 n ( y ( i ) − y ˉ ( i ) ) × ( 1 − tanh 2 ( w x ( i ) + b ) ) × x ( i ) = − ∑ i = 1 n ( y ( i ) − y ˉ ( i ) ) × ( 1 − ( y ˉ ( i ) ) 2 ) × x ( i ) \begin{align*}
\nabla{E(\mathrm{w})}&=-\sum_{i=1}^{n}\left(y^{(i)}-\bar{y}^{(i)}\right)\times \tanh'(w x^{(i)}+b)\times x^{(i)} \\
&= -\sum_{i=1}^{n}\left(y^{(i)}-\bar{y}^{(i)}\right)\times\left(1-\tanh^2(w x^{(i)}+b)\right)\times x^{(i)} \\
&= -\sum_{i=1}^{n}\left(y^{(i)}-\bar{y}^{(i)}\right)\times\left(1-(\bar{y}^{(i)})^2\right)\times x^{(i)}
\end{align*}
∇ E ( w ) = − i = 1 ∑ n ( y ( i ) − y ˉ ( i ) ) × tanh ′ ( w x ( i ) + b ) × x ( i ) = − i = 1 ∑ n ( y ( i ) − y ˉ ( i ) ) × ( 1 − tanh 2 ( w x ( i ) + b ) ) × x ( i ) = − i = 1 ∑ n ( y ( i ) − y ˉ ( i ) ) × ( 1 − ( y ˉ ( i ) ) 2 ) × x ( i )


 支付宝
支付宝

