0x00 神经元
神经元和感知器本质上时一样的,只不过神经元内部用的激活函数不是阶跃函数而是sigmoid或者tanh这样的激活函数。sigmoid函数的定义如下:
sigmoid(x)=1+e−x1
这是一个非线性函数,其值域为(0, 1),其导数为:
y′=y(1−y)
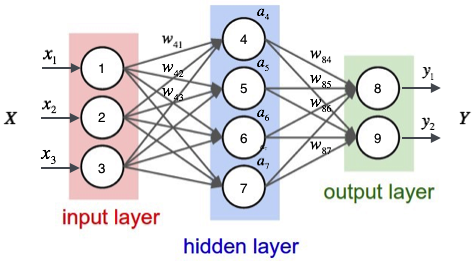
我们先来看一个神经网络:

左边红色的一层为输入层,用于接收输入的数据,最右边绿色的一层为输出层,外界从此获取预测值的输出。二者之间即为隐藏层,对外部而言是不可见的。在上图中,w41表示从神经元1到神经元4的权值,a4表示隐藏层神经元4的输出,其余的标号同理可得。由此我们可以有如下神经网络输出的形成过程:
a4=sigmoid(w41x1+w42x2+w43x3+b4)
在前文线性单元和梯度下降一节,我们已经提到可以将后面的偏差项b看做是一个输入值永远为1的特殊的w,由此我们把b改写成w4b可以有:
a4=sigmoid(w41x1+w42x2+w43x3+w4b)
由此将其转换成矩阵形式有:
a4=sigmoid([w41,w42,w43,w4b]x1x2x31)令w4=[w41,w42,w43,w4b],x=x1x2x31则有a4=sigmoid(w4⋅x)
将上图中我们隐藏层的4个神经元写成矩阵的形式,可有:
a=a4a5a6a7=sigmoidw41w51w61w71w42w52w62w72w43w53w63w73w4bw5bw6bw7bx1x2x31
将前面一组满是w的矩阵记为W1,由此,我们就可以得到:
a=sigmoid(W1⋅x)
同理,继续向下一层,我们可以得到整个神经网络的输出y:
y=[y1y2]===sigmoid([w84a4+w85a5+w86a6+w87a7+w8bw94a4+w95a5+w96a6+w97a7+w9b])sigmoid[w84w94w85w95w86w96w87w97w8bw9b]a4a5a6a71sigmoid(W2⋅a)
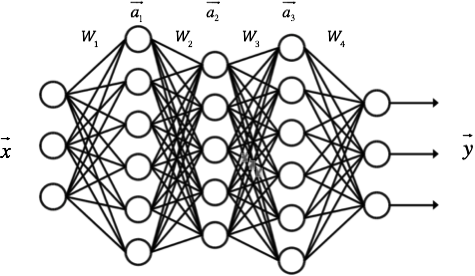
每一层的算法都是一样的,上一层的输出就是下一层的输入,由此我们可以推广一个有更多层的神经网络的算法,如下:
上图中神经网络每一层的输出向量计算即为:
a1a2a3y=f(W1⋅x)=f(W2⋅a1)=f(W3⋅a2)=f(W4⋅a3)
其中f(x)即为激活函数。
0x01 反向传播算法
反向传播算法主要用于训练神经网络。按照之前所说,我们取所有输出层结点的误差平方和作为误差函数:
Ed≡21i∈outputs∑(ti−yi)2
依据随机梯度下降法,我们需要对误差函数进行优化:
wji←wji−η∂wji∂Ed
由此我们需要求得Ed对每个权重值wji的偏导数。
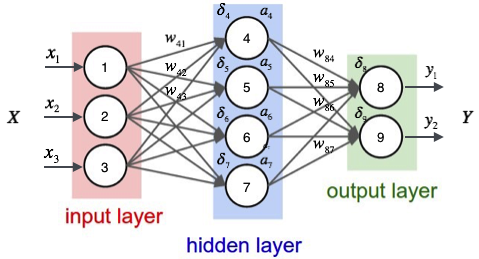
wji表示从神经元i到下一层神经元j的连接的权重矩阵。由上图可以看出wji仅能通过影响结点j的输入来影响网络的其他部分。例如上图中w41只能通过影响结点4的输入值(也就是结点1的输出值)来影响网络的其他部分。由此,我们记netj为结点j的加权输入,由此可得:
netj=i∑wji⋅xji
由此,我们可以有:
∂wji∂Ed=∂netj∂Ed∂wji∂netj=∂netj∂Ed∂wji∂(i∑wjixji)=∂netj∂Edxji
注意在上式中第二步到第三步的推算,对那个和式求偏导数的时候,不是wji的那一项,比如wj(i−1),对wji求偏导数就等于0了,就没有了,所以整个和式的最终求导结果为xji。
对于上式中∂netj∂Ed的推导,则需要分为2种情况,输出层和隐藏层。对于输出层来说,由误差值的计算方法可得,最终的误差Ed直接与输出层netj的输出值yj有关:
Ed≡21i∈outputs∑(ti−yi)2
Ed是yi的函数,而且yi是netj的函数,于是我们可以有:
∂netj∂Ed=∂yj∂Ed∂netj∂yj
对于第一项:
∂yj∂Ed=∂yj∂(21i∈outputs∑(ti−yi)2)=∂yj∂(21(tj−yj)2)=−(tj−yj)
对于第二项:
∂netj∂yj=∂netj∂sigmoid(netj)=yj(1−yj)
由此:
∂netj∂Ed=−yj(tj−yj)(1−yj)
此后我们将上面2式代入∂wji∂Ed,解得:
∂wji∂Ed=∂netj∂Edxji=−yj(tj−yj)(1−yj)xji
令δj=−∂netj∂Ed,也就是一个结点的误差项δ是整个网络的误差Ed对这个结点输入netj的偏导数的相反数。则有:
δj=yj(tj−yj)(1−yj)
将上述推导带入随机梯度下降公式,可有:
wji←wji−η∂wji∂Ed=wji+η(tj−yj)yj(1−yj)xji=wji+ηδjxji
对于隐藏层节点来说,首先我们来明确一个概念——下游节点(Downstream)。节点j的下游节点就是下一层与节点j直接相连的节点。在上图中,对于节点4来说,它的直接下游节点是节点8和节点9。由此我们可以发现,隐藏层的节点4的输出只能影响到节点8和9,然后再间接影响到Ed。由此我们定义节点j的所有直接下游节点集合Downstream(j),设netk为节点j下游节点的输入,要注意的是这个输入不光节点j的输出哦,还有与j同层的其他节点的输出。由此我们可以说netk是netj的函数,而Ed又是netk的函数,由此我们可以有:
∂netj∂Ed=k∈Downstream(j)∑∂netk∂Ed∂netj∂netk=k∈Downstream(j)∑−δk∂netj∂netk=k∈Downstream(j)∑−δk∂aj∂netk∂netj∂aj=k∈Downstream(j)∑−δkwkj∂netj∂aj=k∈Downstream(j)∑−δkwkjaj(1−aj)=−aj(1−aj)k∈Downstream(j)∑δkwkj
注:由0x00 神经元一节所述,aj表示隐藏层神经元j的输出:
aj=sigmoid(Wx)
上式中的x为上一个隐藏层的输出,也是当前神经元的输入。所以实则:
aj=sigmoid(netj)
对于隐藏层的下一层来说,下一层的输入就是上一层的输出,所以下一层的输入netk则有:
netk=wkj⋅aj
依据sigmoid函数的导数公式,有了上述第3个等号到第4个等号的推算。
将δj=−∂netj∂Ed代入上式可有:
δj=aj(1−aj)k∈Downstream(j)∑δkwkj
由此我们可以总结出对于某个节点的误差计算公式:
\delta_j=\left\{
\begin{array}{ccl}
y_j(t_j-y_j)(1-y_j) & \mbox{for}
& j \in \text{output layer} \\
a_j(1-a_j)\sum_{k\in \text{Downstream}(j)}\delta_kw_{kj} & \mbox{for} & j \in \text{hidden layer}
\end{array}
\right.
我们再回过头来看这幅图:
对于输出层节点8来说,其误差值δ8即为:
δ8=y1(t1−y1)(1−y1)
对于隐藏层节点4来说,其误差值δ4即为:
δ4=a4(1−a4)(δ8w84+δ9w94)
最后依据下式更新w的值:
wji←wji+ηδjxji
0x02 检查神经网络是否出错
对于梯度下降算法:
wji←wji−η∂wji∂Ed
我们真正要保证的是这个偏导数∂wji∂Ed的正确性,依据导数的定义:
f′(x)=ϵ→0lim2ϵf(x+ϵ)−f(x−ϵ)
对于任意的导数值我们都可以用右边的等式来进行计算,我们没法求解极限,但是我们只要把ϵ取得足够小就行了,让其大致地在这个区间范围内,我们就可以认为其值是正确的:
∂wji∂Ed=ϵ→0lim2ϵf(wji+ϵ)−f(wji−ϵ)≈2ϵf(wji+ϵ)−f(wji−ϵ)
0x03 训练MNIST
代码过长,参见我的GitHub Gist:
Implement a neron network from very beginning
0x04 为什么没有TensorFlow跑得快
- 全部使用python编写,语言本身效率低,而TensorFlow底层计算全部基于C++编写的动态链接库,TensorFlow python端仅是一个用于与底层库交互的接口,实际的计算工作全部都是在底层库中完成的。
- 全部基于CPU计算,TensorFlow GPU版可以完成基于GPU的计算,众所周知,GPU的浮点计算速度远高于CPU。
- 没有使用向量化编程,没必要定义太多复杂的对象,直接把数学计算实现了就可以了。
- 没有使用SGD(随机梯度下降算法)