Java 分层编译
0x00 前言
一开始接触到分层编译是因为我们这的服务每次发布/重启后都会短暂地出现CPU满线程池满的情况,然后过一段时间又能自动恢复。经排查后是因为启动时JVM将部分热点代码编译为机器代码导致的,这个过程中JIT编译器会占用大量的CPU。
一个Java的源代码文件变成可直接执行的机器指令,需要经过两段编译,第一段是把.java文件转换成.class文件。第二段是把.class文件转换为机器指令。
第一段的编译相对固定,也就是将Java代码翻译为字节码并打包为jar的过程。而字节码的执行则有两种方式,第一种是由解释器(Interpreter)即时解释执行,第二种则是由JIT编译器编译执行。具体采用哪种执行方式则主要看当前的代码是否为「热点代码(Hot Spot Code)」。当JVM发现某个方法或代码块运行特别频繁的时候,就会认为这是热点代码。此后,JIT会把部分热点代码的class直接编译为本地机器相关的机器码,并进行优化,然后再把翻译后的机器码缓存起来,以备下次使用。JIT的运行则主要依赖于运行时的profiling信息,由此则被称为Just-in-time Compilation,也就是即时(运行时)编译。
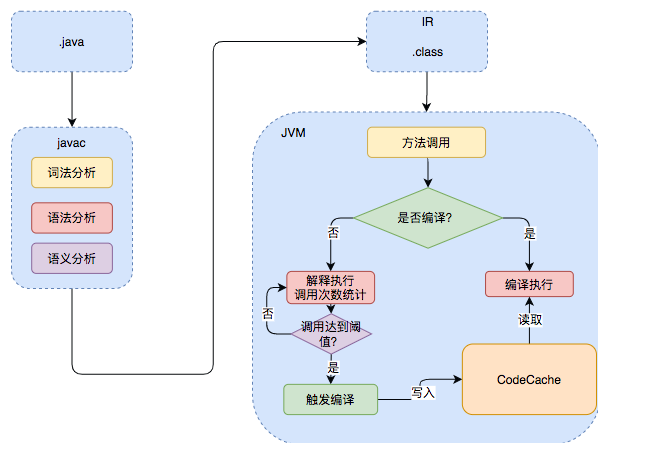
Code Cache的增长过程就像ArrayList一样,一开始分配一个初始的大小,此后随着越来越多的代码被编译为机器码,code cache不够用了之后,就会引发扩容。默认的初始大小是2496KB,最大大小是240MB,二者可分别通过JVM参数-XX:InitialCodeCacheSize=N和-XX:ReservedCodeCacheSize=N进行设定。
自Java 9开始,Code Cache的管理被分为了三个区域:
- non-method segment:存储JVM内部代码,大小可使用
-XX:NonNMethodCodeHeapSize参数配置 - profiled-code segment:C1编译后的代码,特点是生命周期较短(随时都有可能升级到C2编译),大小可使用
-XX:ProfiledCodeHeapSize参数配置 - non-profiled segment:C2编译后的代码,特点是生命周期较长(因为极少发生反优化降级),大小可使用
-XX:NonProfiledCodeHeapSize参数配置
Code Cache分区的好处是降低内存碎片的产生,提高运行效率。一般来讲,假如我们设定Code Cache的最大大小是N的话,那么首先会预留好non-method segment区域,因为这块是JVM内部代码,大小相对固定。此后,对于剩余的大小,由profiled-code segment和non-profiled segment两个区域进行平分。
0x01 分层编译
JVM中集成了两种JIT编译器,Client Compiler和Server Compiler。之所以叫client, server是因为在一开始设计这俩编译器的时候,前者是设计给客户端程序用的,就比如像idea这种运行在个人电脑上的Java程序,不会长时间使用,反而更注重应用的启动速度以及快速达到相对较优性能。而后者则是设计给服务端程序用的,就比如一个spring后端应用,这类可以长期驻守并通过长时间的profiling获取应用使用信息的应用。有这些运行时的profiling数据则可以做更全局更激进的优化,以此来达到最高性能。
HotSpot虚拟机带有一个Client Compiler——C1编译器。这种编译器启动速度快,但是性能相对Server Compiler来说会差一些。Server Compiler优化后的性能要比Client Compiler高30%以上。HotSpot虚拟机则带有两个Server Compiler,默认的C2以及Graal。Graal是从JDK9开始引入的一个全新的Server Compiler,可以通过Java虚拟机参数-XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler启用。
0x00 分层编译(Tiered Compilation)
在Java 7以前,需要开发者根据服务的性质手动选择编译器。对于一些需要快速启动的或者不需要长期运行的服务,可以采用编译效率更高的C1,反之对于那些对峰值性能有要求的后端服务,则可以采用优化效果更好的C2。自Java 7开始,则引入了分层编译(Tiered Compilation),目的是为了在二者之间做一个平衡。
JVM将分层编译分为了五个层级:
- Interpreter:解释执行
- C1 NO profiling:执行不带profiling的C1代码
- C1 LIMITED profiling:执行仅带方法调用次数以及循环回边执行次数profiling的C1代码
- C1 FULL profiling:执行带所有profiling的C1代码
- C2:执行C2代码
profiling同样是个耗时的过程,因此,从执行速度而言,1层>2层>3层
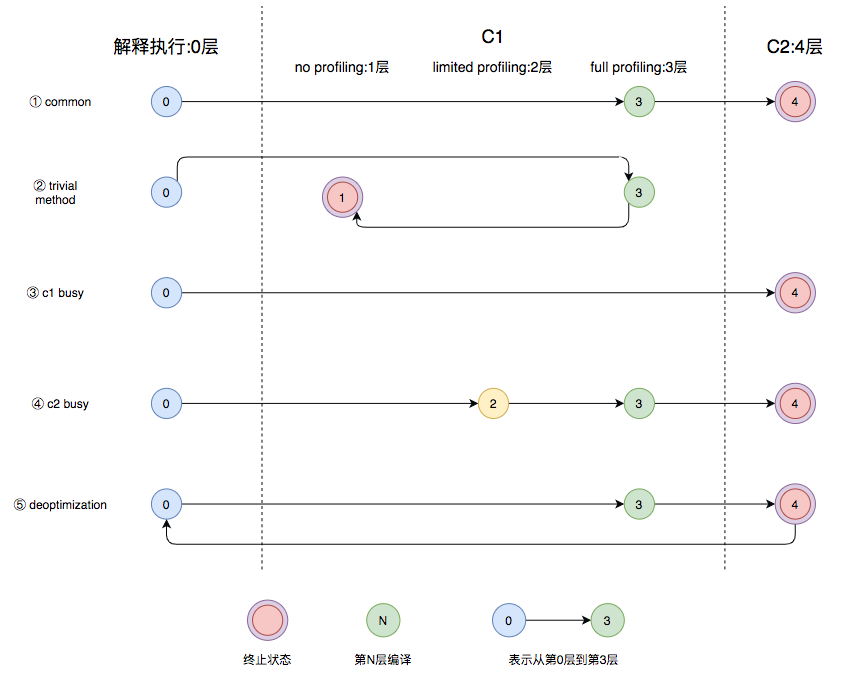
正常的编译路径是这样的,先解释执行(0层)、再使用C1编译执行并带所有的profiling(3层),最后再使用C2编译执行(4层)。但是,
- 如果当前方法过于平凡(trivial),方法体很小或者无从profile,就会从3层流转到1层,直接使用没有profiling的C1代码,并在此终止。
- 如果C1编译器忙的话,就会直接使用C2编译。同理,如果C2编译器忙的话,就会回转到2层,再流转到3层,并等他不忙的时候,再使用C2编译。之所以先流转到2层的原因是为了减少在3层的时间,因为3层的执行效率相对2层较慢。而且如果C2忙的话,也说明大部分方法仍在3层排队等待C2的编译。
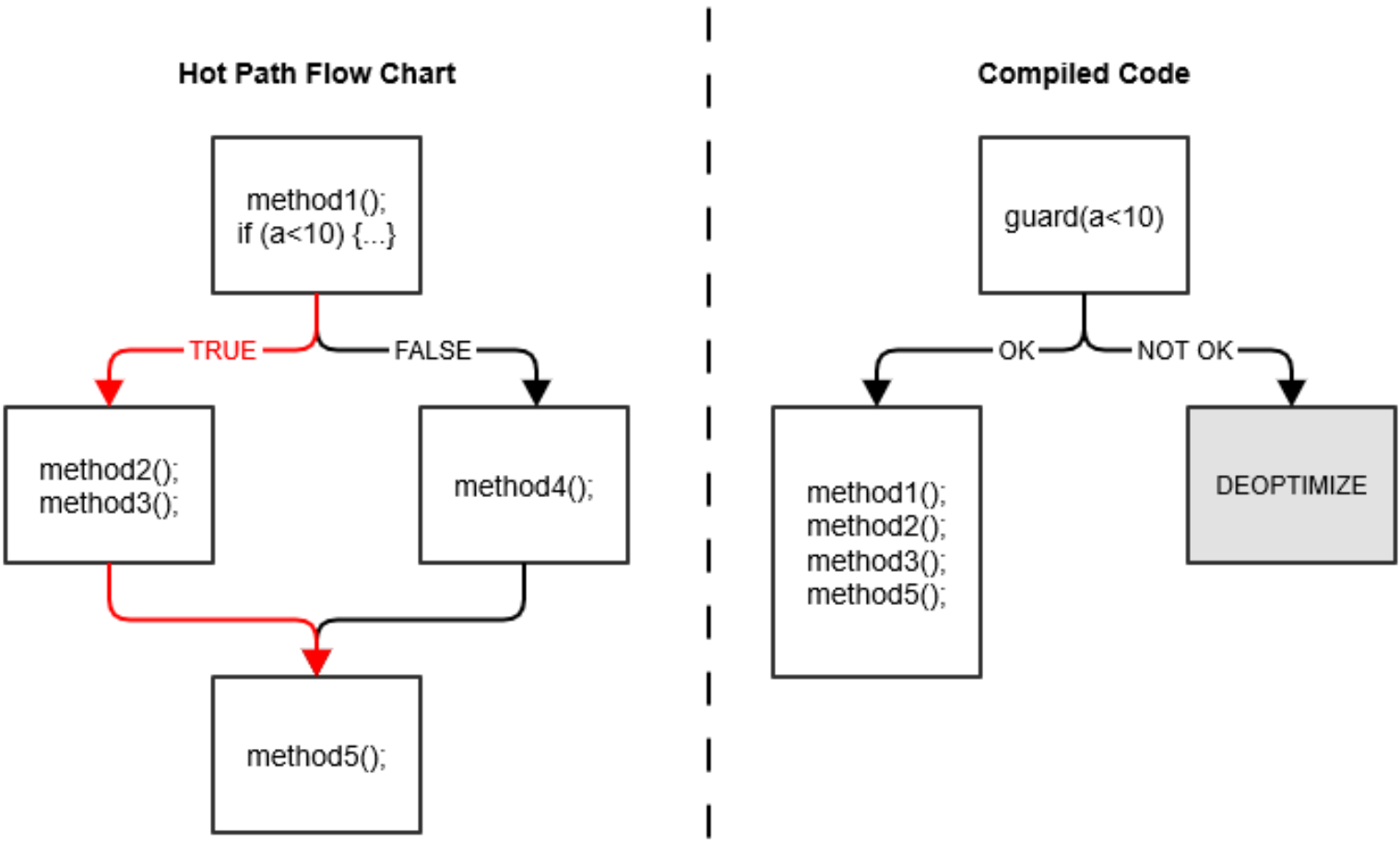
- 如果C2做了一些比较激进的优化,比如分支预测,然后在实际执行中发现预测出错,这个时候就会进行「去优化」,重新进入解释执行。如下图,在运行过程中,编译器发现a总是小于10,一直在走左侧红色分支。此时,编译器就会笃定未来大概率还是走这个分支,于是就会省去
if判断将代码直接组合优化。而对于a≥10的情况,就会重新解释执行。

0x01 性能对比
C1, C2以及分层编译出来的结果,性能到底相差多少呢?
编译速度
本节直接搬运了这篇文章里的结论:Startup, containers & Tiered Compilation。这篇文章同时包含了使用JDK Mission Control工具测量JIT编译时间的方法,值得一看!
作者用了Spring官方提供的一个测试项目——Spring PetClinic——来测算C1, C2两个编译器的编译时间。结论如下:
| C1+C2 | C1 only | |
|---|---|---|
| # compiled methods | 6,117 | 5,084 |
| # C1 compiled methods | 5,254 | 5,084 |
| # C2 compiled methods | 863 | 0 |
| Total Time (ms) | 21,678 | 1,234 |
| Total Time in C1 (ms) | 2,071 | 1,234 |
| Total Time in C2 (ms) | 19,607 | 0 |
| # methods comp. time > 1ms | 950 | 154 |
| # methods comp. time > 10ms | 201 | 5 |
| # methods comp. time > 100ms | 54 | 0 |
| Max compilation time (ms) | 738 | 29 |
如上表所示,C2编译了863个方法花了19.6s,而C1编译了5254个方法仅花了2.1s,二者编译速度上的差距还是非常大的。
程序运行性能
本节直接搬运了这本书里面的结论:Chapter 4. Working with the JIT Compiler,具体可参考「Basic Tunings: Client or Server (or Both)」一节
作者用了一个servlet应用,在不同的编译模式和预热时长下,测算其每秒的吞吐量。结论如下:
| Warm-up period | -client | -server | -XX:+TieredCompilation |
|---|---|---|---|
| 0 seconds | 15.87 | 23.72 | 24.23 |
| 60 seconds | 16.00 | 23.73 | 24.26 |
| 300 seconds | 16.85 | 24.42 | 24.43 |
随着预热时间的增加,编译器profiling收集的信息愈发全面,随之而来的优化也愈发彻底,可见服务的吞吐量也会逐步上升。
同时,C2编译出来的代码的性能要显著好于C1,在开启分层编译的模式下,随着运行时间的变长,性能趋向于C2的最优性能。
TL;DR
这本书里面的实验说实话做得挺奇怪的。如果我既想论证C2优化后性能好于C1,又想论证C1的编译性能好于C2,并以此来说明分层编译的必要性,那么我会用同一个应用测试二者的编译时间和运行性能。而他偏偏用了不同的应用做了这两个实验,我不知道作者在回避什么,还是说对于这个应用来说编译时间上的差距不明显,要换个更明显的测试用例。
0x02 编译优化
0x00 方法内联(Inlining)
众所周知,面向对象的设计就少不了封装,自然也少不了getter/setter:
1 | public class Point { |
触发一次函数调用的成本是相对高昂的,因为少不了栈帧的切换。
1 | Point p = getPoint(); |
如上例,当执行到p.getX()的时候,程序就需要保存当前方法的执行位置,然后创建并压入getter的栈帧,在getter的栈帧中完成对p.x的访问和返回,再弹出栈帧,恢复当前方法的执行。执行到p.setX(...)同理。
由此,编译器可以直接将getX()和setX()方法内联,以提升编译后的执行效率,优化后实际执行的代码如下:
1 | Point p = getPoint(); |
这篇文章中实测,通过-XX:-Inline取消内联优化后的性能损失超过50%。
编译器主要通过方法大小来判断该方法是否有内联优化的价值。首先,如前所述,编译器会在运行时进行profiling,对于热点代码而言,如果该方法的字节码大小小于325 bytes(或由参数-XX:MaxFreqInlineSize=N指定),就会进行内联。对于非热点代码而言,如果方法的字节码大小小于35 bytes(或由参数-XX:MaxInlineSize=N指定),就会进行内联。
一般来说,内联的方法越多,生成代码的执行效率越高。但是,内联的方法越多,编译时间也就越长,程序达到峰值性能的时刻也就越晚。
0x01 循环优化
0x00 循环展开(Loop Unrolling)
CPU是按流水线(pipeline)来执行指令代码的。像打螺丝的流水线工人一样,CPU是坐在那里不动的,指令就像流水线上的零件。当开始运行一个方法时,CPU会将这个方法的指令从主内存加载到CPU缓存中,就好比把所有的零件按序摆到流水线上。此后,流水线开始转动,零件流经工人(CPU)面前,工人(CPU)打好螺丝之后(执行指令)再放回到流水线上。随着流水线的转动,打好螺丝的零件就会落到尽头的箱子(主内存)里,然后流水线还会继续带来下一个零件,等待组装。
如果能一直按流水线的顺序执行,效率无疑是最高的。因为下一条指令就在流水线上,马上就能就绪。但是,循环的存在,就会打破这一顺序。
考虑如下Java代码:
1 | public class LoopUnroll { |
编译后的字节码表示了CPU在执行指令时的流水线:
1 | public static void main(java.lang.String[]); |
流水线转动,CPU自上而下执行流水线上的代码。因为发生了循环,当执行到第35行代码时,goto指令会重新把CPU带回到第18行代码。就好比流水线发生了倒转。让流水线倒转的成本是相比让流水线按一个方向一直转下去要高的。因为你需要先让流水线停下,然后把它倒转到某一方位,然后再开始正转。CPU也不例外,发生倒转(前向跳转,back branch)时,CPU需要先保留下当前的流水线现场,记住自己是从35行代码处想要倒转的。此后,重新从主内存中读取跳转指令地址(第18行)后的指令,再将其加载到流水线中执行。这个过程中带来的性能损失不亚于一次CPU的cache miss。
为了让流水线尽可能少地倒转,JIT编译器会进行循环展开优化,即尽可能少地减少循环的次数。如上例,编译器优化后的代码就类似:
1 | public class LoopUnroll { |
但是,如果我们把上例中循环的计数器i由int类型改为long类型,循环展开就不会被发生。主要是JVM暂时不支持对long类型循环计数器的优化,原因是因为JVM的一些优化必需处理int类型溢出的情况,而处理的方式就是在内部简单地把int类型的计数器提升为long类型,如果要支持对long类型循环计数器的优化的话,就必需去考虑long类型溢出的情况,而目前没有比long更大的整数类型可以低成本地处理这一问题。
此处原因主要参考了文章:Optimize loops with long variables in Java
除此之外,使用long类型的循环计数器,还会引入启发式安全点检查(heuristic safepoint check)和全量的数组范围检查(range check),进一步降低循环的运行效率。这篇文章中指出,同样的逻辑,使用long做循环计数器比使用int慢64%左右。
0x01 前向跳转时的安全点去除(Safepoint Check)
安全点是JVM加在程序代码中的一些特殊位置,标记当程序运行到此处时,所有对当前代码块内部变量的修改动作都已完成。此时JVM可以安全地中断当前线程的运行,并进行一些额外操作,比如GC对内存进行换代,以及所有会触发STW(Stop-The-World)的操作(例如full GC、前文所述的去优化、dump线程内存等)。
如果是解释执行的话,安全点可以天然地安插在字节码之间(in-between bytecodes),也就是当前字节码执行完成,下一字节码执行之前。但是,对于经过JIT编译器编译过的代码,就必需采用一些启发式的方法来分析并安置安全点——循环的前向跳转发生之前,就是一个理想的位置。
考虑如下代码:
1 | private long longStride1() |
编译后的代码中可以看到在每一次循环执行完之后都有一次安全点检查:
1 | // ARRAY LENGTH INTO r9d |
那为什么int类型的循环计数器没有安全点检查呢,因为出于循环性能考虑,JVM给优化掉了。如果你想强制JVM安插安全点的话,可以把循环的步长设置为一个变量:
1 | private long intStrideVariable(int stride) |
多线程程序的运行,是从一个安全点到另一个安全点的。线程1进入自己的安全点后,会暂停并等待线程2线程3也进入下一个安全点,直到所有线程都进入各自的安全点后,再一起向下执行。这么做的好处就是中间有一块空挡,所有人都安全地停下了,JVM就可以进行一些诸如GC这样的全局操作。
但是,如上文所述,对于int类型的循环,JVM优化掉了前向跳转时的安全点,那么如果这个循环非常耗时的话,就会出现其它所有线程都已到达安全点,唯独在等这一个循环线程的情况。
这一情况的外在表现是某一次STW的时间特别长。亦或者你明明开启了多线程,每个线程的任务也都没有完成,但是跑着跑着就发现只有一个线程在运行了。
bug示例:
为解决这一问题,可以使用JVM参数-XX:+UseCountedLoopSafepoints,使用该参数后,对于每N次循环,JVM都会强制加上一个安全点。不过,依据oracle的文档,只有极少数场景下,程序能从中受益。
如果你要排查某次STW耗时极长是不是因为在等循环线程的安全点检查导致的话,可以通过添加JVM参数-XX:+SafepointTimeout -XX:SafepointTimeoutDelay=1000,加上这两个参数后,安全点检查等待的时间超过1000ms,JVM就会打印超时日志,示例如下:
1 | # SafepointSynchronize::begin: Timeout detected: |
需要注意的是,对于安全点检查的优化,只针对于计数循环(counted loop),对于非计数循环,每次循环完成后,都会安插安全点。
此外,如果你的JVM运行在debug模式,是不会消除安全点检查的,也就是说即便你线上程序有如此bug,你在debug模式下也复现不出来。
0x02 Loop Strip Mining
要读这一节,你首先要完整地读完上一节。此外,这是Java 10中才引入的新技术。没写中文名的原因是我还没想出一个比较好的翻译。
上一节中,我们讲到对于int类型做循环计数器的计数循环来说,JIT会消除掉前向跳转时的安全点,这有可能导致多线程场景下,所有线程停下来等这一个循环线程抵达下一个安全点的情况。这种偶发且长时间的STW问题对于低时延的GC来说是非常敏感的,因为这很容易给人一种GC慢了的感觉。同时也会拖累其它快的线程发生安全点等待。除此之外,如果使用-XX:+UseCountedLoopSafepoints参数来强制循环N次后加入安全点,又会影响循环的性能。
为了在二者之间作出一个平衡,Java 10中引入了一项新技术——Loop Strip Mining,这本质上一个循环分区技术,通过profiling统计出别的线程大概运行多久能抵达下一个安全点,同时找出在当前线程的长循环中,循环多少次能匹配这个平均抵达安全点的时间,然后在循环这些次数之后,安插安全点,以尽可能地避免单线程中长循环不经过安全点拖累所有人的问题。
1 | for (int i = start; i < stop; i += stride) { |
优化后的伪代码例如:
1 | i = start; |
0x03 边界检查消除(Range Check Elimination)
数组边界检查的目的在于判断当前的数组对象访问有无越界,发生越界的话,好给你抛出一个ArrayIndexOutOfBoundsException。
考虑在循环内访问数组的情况:
1 | for (int index = Start; index < Limit; index++) { |
每循环一次,都要检查下这个index有没有超过数组Array的边界。这无疑是耗时的。为此,JIT会尽可能地消除循环过程中的边界检查。
这项技术把一个循环拆分为三部分,Pre-loop, Main loop and Post-loop(前序循环、主循环和后序循环)。它会先运行循环,并附带数组边界检查,在执行中依据步长的变化和数组的最大长度推断一个可以不用进行边界检查的最大循环次数N,这个过程就是前序循环。然后接下来的N次,都不再执行边界检查,也就是主循环。当过了N次之后的循环,再访问数组时则会带上边界检查,也就是后序循环。
上述代码经编译器优化后就类似:
1 | int MidStart = Math.max(Start, 0); |
该优化的执行有几个前提条件:
-
循环访问的数组在循环中不发生变化
-
循环的步长在循环中是不变的
-
访问时的数组下标呈循环计数器的线性关系
1
2
3for (int x = Start; x < Limit; x++) {
Array[k * x + b] = 0;
}在上例中,
k和b都为循环中不变的常量,x为循环计数器,k * x + b的访问就是呈循环计数器线性关系的访问。 -
当前循环在JIT profiling过程中被判定为热循环
0x04 循环判断外提(Loop Unswitching)
循环判断外提主要用于减少循环中的判断次数:
1 | for (i = 0; i < N; i++) { |
上述代码可被编译器优化为:
1 | if (x) { |
这一优化,可以在编译为字节码时通过静态分析完成,无需借助运行时的profiling和JIT编译器。
0x02 逃逸分析(Escape Analysis)
逃逸分析(Escape Analysis, EA)是一个代码分析过程,基于分析结果可以做很多有意思的优化,比如标量替换、锁消除等等。
如下的这篇文章详细讲解了JIT是怎么利用逃逸分析的结果进行各种优化的,但内容偏原理性,且相对高深不易读懂,有兴趣可以看看:
SEEING ESCAPE ANALYSIS WORKING
如果想简单了解下,可以看下面我写的部分
0x00 标量替换(Scalar Replacement)
如果一个对象没有被方法外部访问,并且它还可以被拆分的话,那么当程序执行的时候,就不会创建这个对象,反而直接创建它的成员变量来替代。将对象拆分后,可以分配对象的成员变量在栈或寄存器上,原本的对象就无需分配内存空间了。
1 | public void foo() { |
编译器优化后:
1 | public void foo() { |
在上例中,优化前代码中的MyObject object = new MyObject();是在堆上分配内存,后序内存的回收则交由GC完成。而优化后代码中的int x = 1;,是直接在当前方法栈中分配内存。栈内的内存在当前方法的栈帧执行结束之后,就被自动释放了。由此,就无需GC对其进行垃圾回收,同时栈内内存访问比堆内内存访问速度快,二者结合以此来提升程序的运行效率。
编译器在执行上述优化的过程中,会在运行时进行逃逸分析,判断对object对象的访问是否超出了当前方法的范围(escaping)。比如是否被当前方法作为返回值返回,或者作为入参传给了其它方法,或者被传递给了多个线程访问。如果编译器认定其没有发生逃逸(non-escaping),上述优化就会被执行。
受制于当前的EA实现,如果对象在访问前通过了控制流,那即便我们人为看上去没有发生逃逸,编译器也不会对其进行优化。如下例,o对象并没有发生逃逸,但实际并不会对其进行优化。
1 | public void foo(boolean flag) { |
标量替换对性能的提升能有多少?
1 | Benchmark Mode Cnt Score Error Units |
这篇文章对上述两例进行了对比测试。ScalarReplacement.single是发生了标量替换后的性能结果,ScalarReplacement.split是加了控制流骗过EA没有发生标量替换后的性能结果。
个人认为,上述的ns/op值没有意义,因为不是在相同代码环境下做的对比实验,ScalarReplacement.split的结果有if-else判断带来的性能影响。由此不能用于对比标量替换所带来的性能上的提升。
反倒gc.count和gc.time的提升相对有价值一点,因为标量替换带来的最终好处就是省去了堆上内存分配和GC的过程。
TL;DR
标量替换与栈上分配
众所周知,就访问速度而言,寄存器>栈内存>堆内存。由此,另有一种基于EA的编译优化策略是栈上分配,对于没有发生逃逸的对象,直接将整个对象存储在栈上。但JVM并没有这么实现,反而使用了标量替换作为替代方案。这么做主要是考虑到了两个因素:
- Java的内存模型中,栈内存只保存原始类型和对象的指针信息,对象的指针指向堆内存中对象实体的地址。在栈内存中分配对象实体,打破了这一模式。
- 对象的存储不仅包括对象成员变量的存储,还包含了对象本身的头结构。不管在栈上还是在堆上分配,只要分配出这样一个对象,就一定会包含其头结构信息的存储。但如果进行标量替换,就省去了头结构,只完成了对其成员变量的分配。
0x01 锁消除(Lock Elision)
一道经典的Java面试题是StringBuffer和StringBuilder的区别,前者是线程安全的,后者是不安全的。原因是前者的append方法使用了synchronized关键字修饰,加锁了。
但实际上,在以下代码测试中,StringBuffer和StringBuilder的性能基本没什么区别。这是因为在局部方法中创建的对象只能被当前线程访问,无法被其它线程访问,所以这个变量的读写肯定不会有竞争,这个时候JIT编译会对这个对象的方法锁进行锁消除。
1 | public static String getString(String s1, String s2) { |
锁消除的依据是逃逸分析,未发生逃逸的一个必要条件是当前对象仅对一个线程可见。由此,对于未发生逃逸的对象内部操作,就可以进行锁消除,去除同步逻辑以提高效率。
通过JVM参数-XX:-EliminateLocks可禁止编译器进行锁消除优化。这篇文章通过实验测出锁消除后的性能几乎与不加锁版本的代码相同,同时,禁止锁消除优化后,加锁版本与不加锁版本有数十倍的性能差距。
0x03 窥孔优化(Peephole Optimization)
窥孔优化是编译器后期进行的一种优化策略,旨在对局部代码块中的指令进行运算强度削减。这些也都不需要进行profiling,编译器可以直接通过对代码的静态分析来完成。
需要注意的是,窥孔优化是处理器相关的(machine-dependent)。编译器会根据不同处理器的指令集特点来进行优化,也就是说对于不同处理器而言,窥孔优化的结果可能也不一样。
举个例子,Intel公司自2011在其Sandy Bridge架构的CPU中引入了AVX2(Advanced Vector Extensions)指令集,随后在2016年对其进行了扩展,引入了AVX-512指令集。由此,自JDK9开始,JIT就针对该指令集做了专门优化,但默认关闭。自JDK11开始,该指令集优化被默认打开。可以通过JVM参数-XX:UseAVX=N来对其进行设置,N的取值可为:
- 0:关闭Intel AVX指令集优化
- 1:使用Intel AVX level 1指令进行优化(仅支持Sandy Bridge及更高架构CPU)
- 2:使用Intel AVX level 2指令进行优化(仅支持Haswell及更高架构CPU)
- 3:使用Intel AVX level 3指令进行优化(仅支持Knights Landing及更高架构CPU)
JVM运行时会自动检测当前使用CPU架构,然后挑选一个其支持的最高版本的指令集进行优化,也就是自动设置-XX:UseAVX=N中参数N的值。
运用代数或离散数学定律进行优化
1 | y = x * 3 |
用较快的指令替换较慢的指令
例如对于x的平方运算:
1 | x * x |
直接编译后的字节码:
1 | aload x |
其中aload x表示加载标识为x的变量并将其推送到栈上,mul则表示二者相乘,经窥孔优化后的结果可以为:
1 | aload 1 |
其中dup操作表示复制上一条指令的结果并推送到栈顶,相比aload再从内存中加载速度快。
死代码消除
顾名思义就是消除代码中那些抵达不了或者干脆无用的部分
1 | int dead() |
优化后:
1 | int dead() |
0x04 参考文献
Startup, containers & Tiered Compilation
Chapter 4. Working with the JIT Compiler
Deep Dive Into the New Java JIT Compiler – Graal
Optimize loops with long variables in Java
SEEING ESCAPE ANALYSIS WORKING
- 支付宝
- 微信


