C++ 内存对齐总结
0x00 C++ 内存管理机制
0x00 内存布局
如图:
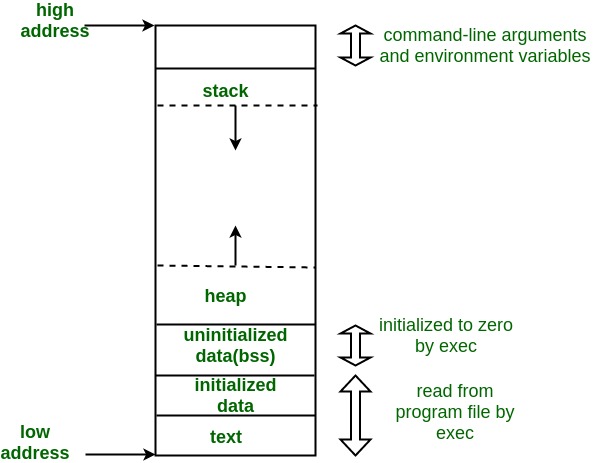
从低地址到高地址(从下往上)依次为:
-
Text Segment(代码段): 英文也可以写为code segment,包含了程序的可执行代码,通常此段是可共享的,以便同样的可执行代码只需要在内存中存储一遍,同时此段是只读的,以防止程序分配内存时将其覆写。
-
Initialized Data Segment(初始化数据段): 有时英文也简写为data segment,用来存放程序的全局变量以及静态变量, 此段可进一步被分为初始化只读区域(initialized read-only area)以及初始化可写区域(initialized read-write area),例如如下两个全局变量:
1
2const char * str = "Hello World"; // 将会存储在初始化只读区域
char * str = "Hello World"; // 将会存储在初始化可写区域 -
Uninitialized Data Segment(未初始化数据段): 又称为bss段,此段数据将会在程序开始执行以前被内核初始化为0,此段包含了所有未在程序代码中显式初始化的全局变量和静态变量,例如:
1
static int i; // 未被显式初始化的静态变量
-
Heap(堆区): 动态分配内存时所使用的区,也就是在C语言中使用malloc函数开辟free函数回收的内存区域,或者在C++中使用new关键字开辟、delete关键字回收的内存区域。堆区从低地址向高地址增长。
-
Stack(栈区): 栈从高地址向低地址增长,如果栈顶指针与堆顶指针相遇,那么就没有剩余的内存空间可以继续分配了(不考虑虚拟内存技术将部分内存内容转移至硬盘中存储)。栈区存放的是程序栈(program stack),是一个LIFO(Last In First Out后进先出)的数据结构。
栈区存放局部变量(automatic variables又称自动变量),当一个函数被调用时,返回值的地址以及调用时传递的参数信息就会被存储在栈中,然后新调用的函数将会在栈中分配局部变量的存储空间。同时,程序将会为每一次函数调用分配一个新的栈帧(stack frame)。
0x01 堆与栈的区别
- 管理方式不同:栈由编译器自动管理,堆的开辟与释放需要程序员的控制,此过程容易产生memory leak。
- 空间大小不同:对于ARM、x86以及x64机器,栈的默认大小是1MB(此处参考/STACK (Stack Allocations) - MSDN文档),当然我们也可以通过编译器参数
/STACK自行设置其大小,堆在32位系统下最大可以达到4GB的空间。 - 碎片问题:频繁的new/delete势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,他们是如此的一一对应,以至于永远都不可能有一个内存块从栈中间弹出,因为在他弹出之前,在他上面的后进的栈内容已经被弹出了。
- 生长方向:对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向;对于栈来讲,它的生长方向是向下的,是向着内存地址减小的方向增长。
- 分配方式:堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由
alloca函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现。 - 分配效率:栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就注定了栈的效率比较高。 堆分配的机制较为复杂,一般由C/C++的函数库来进行支持,为了分配一块特定大小的内存往往需要先在堆内存中搜索可用的足够大小的空间(考虑碎片问题),如果没有足够大小的空间(例如碎片过多),就可能会通过调用系统功能来进行碎片整理来增加程序可用的空间大小,然后进行返回,可见堆的使用效率要比栈低得多。
0x02 指针和数组的区别
指针和数组在很多地方可以替换着用,但两者是有别的。数组要么在静态区初始化数据段(Initialized Data Segment,例如全局数组)得以创建,要么在栈区创建,数组名对应着一块内存区域,其地址和容量在其生命周期内保持不变。而指针可以指向任意类型的任意内存块,而且可以随时变更其指向,指针操作要远比数组灵活,使用起来也更加危险。
数组可以使用sizeof丈量其大小,而指针不能通过sizeof丈量其所指内存块的大小,C/C++没有办法知道指针所指内存块的大小,除非在申请内存时记住它。
1 | int *p = new int[10]; |
注意当把一个数组作为函数的参数传递时,该数组会自动退化为同类型的指针,如下示例:
1 | void test(int a[10]) |
此时程序将会输出4,即sizeof(int*),而不是40。
0x03 有了malloc和free为什么还要new和delete
malloc和free为C/C++库函数,而new和delete为C++运算符,两者都可用于申请动态内存和释放内存。
对于非内部数据类型而言(例如类的对象),在创建时需要调用其构造函数,在销毁时需要调用其析构函数。malloc和free是库函数而不是运算符,其不在编译器的可控制范围之内,所以编译器无法将执行构造函数和析构函数的任务强加给malloc和free。所以C++语言才需要一个完成动态内存分配和初始化的运算符new和一个完成清理以及释放内存工作的运算符delete。
对于内部数据类型而言(例如int类型),其没有构造与析构的过程,所以对他们而言,malloc和new以及free和delete是等价的。
如果用free释放用new创建的动态对象,那么该对象因无法执行析构函数而可能导致程序出错。如果用delete释放malloc申请的动态内存,结果也会导致程序出错,但是该程序的可读性很差。所以new/delete必须配对使用,malloc/free也一样。
0x01 C++ 内存管理策略
0x00 申请内存时检查内存是否分配成功
在使用new或者malloc申请内存时检查内存是否分配成功,如果不成功new或者malloc将会返回NULL,示例如下:
1 | char *p = new char[10]; |
如果内存分配不成功,最好使程序退出,因为此时多半系统内存已经被耗尽了,这对于应用程序来说往往已经无药可救了,如果不杀死应用程序,它可能会害死操作系统。为了避免进一步的损害建议使用exit(1)使程序退出。
0x01 动态内存申请与释放必需配对
有多少次new就得有多少次delete,否则容易出现memory leak内存泄露,例如如下函数,每次调用都会丢掉sizeof(int)*100大小的内存,而且刚开始时系统内存充足,你看不到任何错误,但是随着运行时间的增长,终有一次程序突然死掉,然后系统提示内存不足。内存错误时隐时现,且改错难度较高,有时候用户想你报告bug,但是开发人员难以在自己机器上复现错误,多半就是产生了内存错误。
1 | void eat_memory() |
0x02 释放内存后将指针置空
在使用delete释放指针所指向内存后,一定要将指针置为NULL,否则该指针将会成为野指针,指向一个被释放过的堆地址,如果其他指针分配的内存恰好又覆盖这个指针指向的内存区域,再次使用该指针可能会诱发系统错误。如果你将这个指针置为NULL了,你delete或free多少次都没关系都不会出错。但是如果你不置空,free多次就会出现问题。
0x03 返回时指针或引用时注意其是否指向栈内存
函数在栈区分配的内存将会在函数执行完成后销毁,如果返回指针或引用指向栈区内存,返回后,这个指针将变为野指针。如下代码:
1 | char * get_string() |
0x02 C++ 内存对齐
0x00 内存对齐原则
- 基本类型数据成员对齐规则:类(class)、结构(struct)或联合(union)的基本类型数据成员,第一个数据成员的位置放在offset为0的地方,以后每个数据成员的起始位置都要从该成员大小或者该成员子成员大小(如数组或者结构体)的整数倍位置开始。
- 结构体作为成员:如果一个结构体里有另一个结构体做数据成员,则这个结构体成员要从其内部最宽基本类型成员的整数倍地址开始存储。(struct A里面包含struct B {int c; double d;};那么struct B应该从8的整数位开始存储)
- 结构体的总大小,也就是
sizeof产生的值,必须是其内部最大成员的最宽基本数据类型的整数倍,否则要补齐。 - union的总大小,为其数据成员最大的那个的大小,因为在同一时刻只有一个成员真正存储在该地址。
- 结构体各个数据成员在内存中的相对顺序就是你在结构体中定义它们时所使用的顺序
0x01 结构体总大小说明
以下默认均为32位机上进行测试,并输出结果:
1 | struct Origin |
使用sizeof输出其大小为8,因为其最宽基本数据成员为int,32位机上int占据4字节,char占据1字节,所以其最终大小要为内部最大成员的整数倍,4+1=5,补齐为4的2倍即为8字节。
0x02 结构体内存对齐实例
以下默认均为32位机上进行测试,并输出结果:
1 | struct Origin |
因为结构体数据成员在内存中的相对顺序就是按照你定义它们时所使用的顺序来的,所以,看struct Origin,其最长数据成员为int b,大小为4字节,两边都是一个1字节的char类型,所以两边的char类型都要各补齐3个字节凑齐4个字节,所以导致最终结构体的总大小为12字节,空间利用率为6/12=50%。
而对于struct Optimized,我们将两个char放在一起了,其紧挨着并各自占据1个字节,补齐2个字节凑齐4个字节,所以最终大小缩减为8字节,空间利用率为6/8=75%。
再考虑一种复杂情况:
1 | struct Common |
这时struct Origin的大小变为了24,原因为当struct中有自定义类型时,选取其中最大的基本类型来进行对齐,计算Origin大小时,首先其中带有自定义类型struct Common,在Common中选取最大的基本数据类型为double,一个double占据8个字节的内存,所以其最终的大小要补齐为8的倍数,首先看其中的结构体Common,Common占据16字节(8+4=12补齐为8的倍数为16),然后Common的16字节+外面char的1字节=17字节,补齐为8的倍数,整个大的结构体占据24字节。
这样,如果不将int a和double b单独放在一个结构体内的话,反而能节省空间,因为省略了内部结构体补齐空间的过程,例如:
1 | struct Optimized |
所以,如果没有极其的必要,最好还是不要在结构体里嵌套结构体。
再补充一点,C++的空类、空结构体、空union也是有大小的,其占据的大小为1字节,这和里面有一个char类型的成员是占据一样多的内存,如下面示例中,两个结构体占据的大小均为1字节。
1 | struct Origin |
0x03 类的内存对齐
以下默认均为32位机上进行测试,并输出结果:
类的内存分布规则还是会按照结构体的来,即便里面有成员函数(非虚函数),其大小依然只算其内部数据成员所占大小,如:
1 | class Origin |
如果其中有虚函数,那就另当别论了,如例:
1 | class Base |
首先,虚函数指针单独搁伙,不与数据成员一块对齐,一个虚函数指针跟普通指针一样占据4字节,如上,Base类中,内存分布应如下:
|<- vptr4 ->|<- 空4 ->|<- char1 ->|<- 空7 ->|<- double8 ->|
|<- 4 + 4 + 1 + 7 + 8 = 24字节 ->|
而不是:
|<- vptr4 ->|<- char1 ->|<- 空3 ->|<- double8 ->|
|<- 4 + 1 + 3 + 8 = 16字节 ->|
一定要注意虚函数指针是单独搁伙的!
同样此时我们再添加一个虚函数,其占据大小也为24字节,因为另一个虚函数指针填充了一开始空出来的那4个字节:
1 | class Base |
带有虚函数的一个类的派生类的大小为基类的大小再加上按基类和派生类中所有基本数据成员最大宽度对齐后的大小,如下:
1 | class Base |
首先我们纵观基类和派生类中,最大的基本数据成员为double类型,其大小为8字节,所以派生类也要按照8字节去对齐,基类大小为24字节,派生类仅多出一个char类型数据,大小为1字节,24+1=25字节,25按照8的倍数对齐的话,需要补齐7个字节,所以派生类大小的结果为32字节。
同样适用于多继承情况下,例如:
1 | class Base |
此例中Derived类的大小为两个基类大小的总和为24+8=32字节,再加上派生类中所处的这个char类型的1字节,为33字节,再加7补齐为8的倍数即为40字节。
0x04 内存对齐的作用
对上面的问题理解完了之后,我们再来思考一个问题,内存对齐的作用究竟是什么,对齐之后不久有些明显的内存的浪费了吗?其实这是在用空间换时间。CPU通常以块读取内存,这个块的大小可能是2、4、6、8字节大小,CPU是一块一块读取的,一读取就是一整块。块的大小就是memory access granularity(内存读取粒度)。
现在我们假设CPU的内存读取粒度为4字节,我们现在要读入下面那个结构体中的int i,长度为4字节的int型数据:
1 | struct mystruct { |
假设说,不用内存对齐,那么它在内存里将会是这样的:
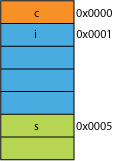
CPU首先从0x0000开始,读取4字节,此时把内存块0x0000-0x0003都放在了寄存器里,这时CPU需要左移一个字节,将0x0000那个内存块剔除掉,然后CPU从0x0004那个内存块开始,再次读入4个字节,此时读入了0x0004-0x0007四个内存块,然后通过右移3个字节,剔除掉右边3个,然后将剩下的这1个字节与寄存器里面的3个字节做OR运算即可得出0x0001-0x0004这4个字节所组成的int类型的数据。这中间CPU读取了2次还做了一次OR运算。
如果内存对齐了,情况就不一样了,如图:
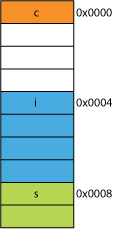
CPU仅需要通过一次读取就可以读取到其中的数据,相比于不对齐的情况,省去了一次读取的过程和一次OR运算的过程,通过内存对齐机制有效提升了CPU访问内存的效率。
0x0 参考文献
Data structure alignment - Wikipedia
Purpose of memory alignment下joshperry的回答 - Stackoverflow
Memory Layout of C Programs - GeeksforGeeks
 支付宝
支付宝- 微信


