Deep Image Retrieval A Survey
导言
文章地址:Arxiv
本文是一篇Survey,主要调研了2012年以来的基于深度学习的图像检索方法。这篇Survey主要是从如下3个科学问题展开:
- 如何使预训练的模型提取出来的特征超过传统数学模型?
- 如果我们使用在别的领域训练过的模型(比如:图像分类)所提取出来的特征来做图像检索的话,如何才能让这些模型保持或取得更好的效果呢?
- 深度特征普遍维度较高,如何才能更好地利用这些特征在大规模图像数据集上取得更好的检索效果呢?
总结
目前来说,现有的DCNN模型的来源主要有二:在别的任务上预训练好的以及fine-tune过的。二者之发展,可参照下图:
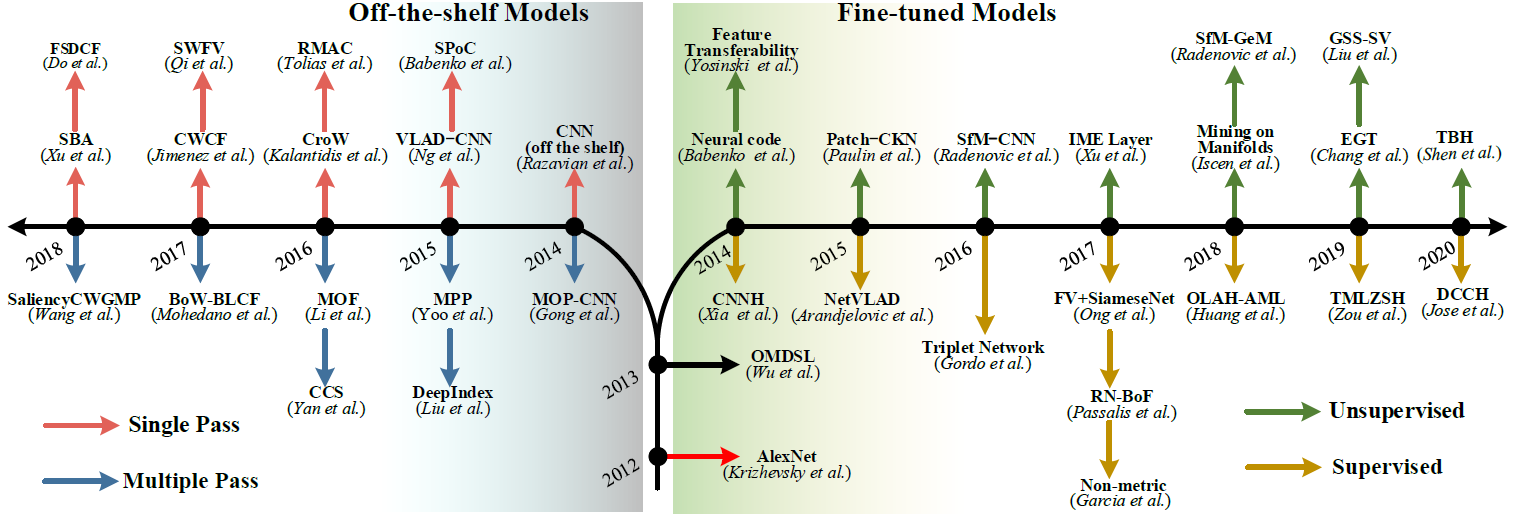
上图中,左侧路线呢是off-the-shelf模型,也就是说,一个预训练好的DCNN模型就直接拿过来,什么也不做,就直接应用到图像检索任务中。在这方面的研究呢,主要集中在提升表现层的输出质量上,相关的工作则有单次通过模型,或多次通过模型(将一张图片拆分为多个子图然后多次通过模型)。而右侧路线呢,则是针对已有模型在检索任务上进行过fine-tune后的模型,工作主要可以分为有监督的学习和无监督的学习两类。
如果从检索效果的提升上来进行划分的话,目前的研究也主要有两个主要的着力点:从网络上下手亦或者从特征上下手。从网络上下手主要包含网络结构的选择以及相关的fine-tune策略等,而从特征上下手,则主要涉及到特征提取和特征增强的相关方法。
而本文呢,主要校验了如下四个领域上的一些工作:
- 网络结构上的提升:越深的网络将会有越强的学习能力,提取出来的特征也更偏向高层的语义抽象。
- 深度特征提取:全连接层和卷积层的感受野是不一样的,卷积层输出更倾向于局部特征,而全连接层则更倾向于全局特征。同时,亦可将二者采用一定规则做一定的融合。融合的方式自然有layer-level和model-level两种。同时在进行深度特征提取时,亦可选择将整张图片进行单次输入,或者将图片拆分成若干子图后进行多次输入。
- 深度特征增强:深度特征增强主要用于提升深度特征的区分度。目前来讲,特征嵌入算法,例如BoW, VLAD, FV,可以将多个局部特征组合成一个全局特征,这些算法可以跟深度特征分开计算(基于预训练的codebook)亦或联合计算(无需codebook)。除此之外,hash算法可以将实数特征转换成二进制码来提高检索的效率。
- fine-tune:常规的深度特征多是基于在图片分类等任务上预训练的模型,在应用到检索领域的时候,其精度就难免受领域切换(domain-shifts)的影响,因此,对神经网络在检索领域上进行fine-tune就显得尤为重要。
目前学界在基于深度特征的图像检索上的研究,主要集中于如下3个基本的科学问题:
- 弥补语义鸿沟(semantic gap):人对图片内容的理解往往是基于一个高层次的认知概念,而从图像中提取出来的特征又较偏低层次。因为弥补二者之间的鸿沟,使训练出来的特征更加偏向高层次和语义感知(high-level and semantic-aware)以最大化地保留图片间的语义相似性,则是目前研究的一个热点问题。目前针对此问题的研究,主要集中在一些特征融合以及特征增强算法上。
- 提升检索的可扩展性:在图像分类任务上的预训练模型提取出来的特征往往可扩展性较低,而且在亟待检索的数据集上的表现也相对较差,所以说,在亟待检索的图像数据集上对神经网络进行fine-tune就显得比较重要。又因为,目前人工标注图片所耗费的成本居高,所以目前优先发展的则是无监督学习。
- 在检索准确率和检索效率之间做出平衡:深度特征的维度越高,所能支持的检索准确率就越高,相反,检索效率也就越差。通过使用一些特征增强算法,例如hash学习,即可解决这一问题。不过hash学习需要仔细地考虑损失函数的设计,以在提升检索效率的同时,最大化地保留检索的精确度。
主流的CNN设计
目前占支配地位的CNN设计就如下四个:AlexNet, VGG, GoogLeNet, ResNet。
- AlexNet:有5个卷积层和3个全连接层,在输入神经网络之前,输入图片往往会被缩放到一个固定大小。
- VGGNet:目前有2个主流版本,VGG-16和VGG-19,前者有13个卷积层,后者有16个,而且所使用的卷积核都比较小(3x3)。在训练的过程中,其会将输入图片进行多尺度的裁切和缩放,这样做就有效地提升了在检索任务中的特征不变性。
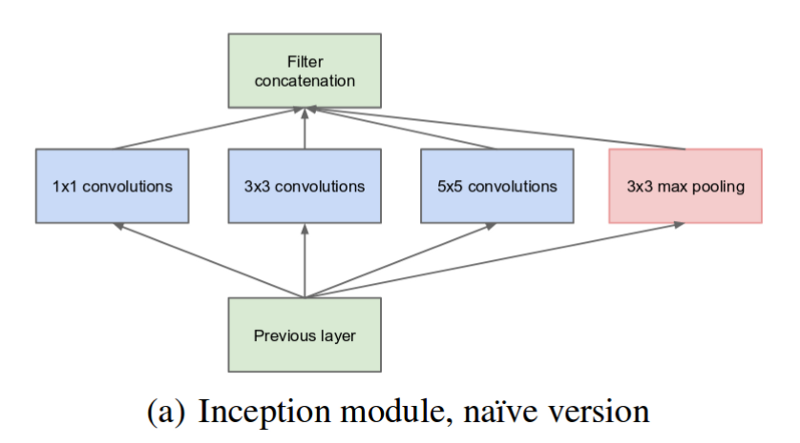
- GoogLeNet:有22层,相对于如上两者,其更深也更宽,但是使用的参数数据较少。其构建了一种名为inception module的水平组件,然后最终将这些水平组件卷积层的输出做了一个聚合,以产生最终的输出结果,如下图所示。同样,其证明了越深层次的网络越有利于学习高层次的抽象信息以及弥补语义鸿沟。
- ResNet:使用了更多的卷积层来学习更抽象的特征,同时使用了一种名为skip connection的结构来解决训练过程中的梯度消失的问题。
本文所调查的工作,不在这些神经网络上,而是如何使用现有的神经网络,来取得更好的检索效果。
使用预训练的神经网络来做检索
**本节主要讲的是,使用在图像分类和图像识别等任务上预训练的神经网络来做图像检索,在这个过程中不会修改神经网络的结构,亦不会对其进行fine-tune。**因为不改神经网络,所以这一节将主要集中在如何提高神经网络输出特征的质量,主要集中在一些特征融合和特征增强算法上。
前馈神经网络的选择
一次通过模型
一次通过模型,是指将整张图片一次完整地通过这个预训练的模型来提取最终的特征。这种方法自然也相对高效一点,而且全连接层的输出和卷积层的输出都可以作为图片视觉特征的最终输出。
全连接层输出的特征往往对原始图像具有全局感受野,在经过归一化和降维后,这些特征往往就被直接用于检索。但是,这些特征往往会不具有对待检索图像中物体的几何不变性(geometric invariance),同时也会缺失空间信息(spatial information)等。由此,又有一些研究提出使用最后一个卷积层的输出作为图像特征,这么做的好处就是提高了特征的区分度。
几何不变性(geometric invariance):平移,旋转,尺度等等。与之对应的还有光度不变性(photometric invariance):亮度,曝光等等。
多次通过模型
多次通过模型,是指将一张完整的输入图片,通过一定的方法拆分成多张子图,然后将这些子图分别通过神经网络获取特征,最终将所有的特征组合成一个最终用于检索的特征的过程。多次通过模型往往有更高的检索精确度,但是效率也会相对较低一点。
同时,对于一张图片,将其分割后的子图可能包含一些完全无用的内容(例如充作背景的蓝天草地等),这些完全无用的内容如果不加以筛除的话,也会作为图片的子图通过神经网络提取特征,而这些特征往往又是无用的,而且会降低检索的效率和精度。因此,有必要对切分出来的子图进行进一步的分析,以筛除无用子图,降低待检索数据集大小的同时,亦可提高检索的精确度。相关的算法,主要涉及一些区域推荐算法(Region Proposal)。区域推荐目前可以通过目标检测器(Object Detector)来实现,例如选择性搜索(Selective Search)和edge box等。亦可通过深度学习的方法来实现,例如区域推荐网络(Region Proposal Networks, RPN)以及卷积核网络(Convolutional Kernel Network, CKN)等。
深度特征选择
从全连接层提取特征
从全连接层提取的特征,经过PCA降维和归一化后即可直接用于图像视觉相似度的测量。单纯地从全连接层提取特征有可能会限制整体的检索精度,因此有人在上面做出过一定改进,例如,将多个全连接层的输出特征拼接起来,作为最终的特征输出。有研究指出,将第一个全连接层的特征与最后一个全连接层的特征拼接起来,得到的组合特征在图片语义表述上可以取得一个由粗到细的提升(coarse-to-fine)。
全连接层的输出特征,往往具有一个全局的感受野,但是又缺少了图像的空间信息,也不能保证局部的几何不变性。对于图像空间信息的补全,可以使用多次通过模型。对于局部特征几何不变性的保证,部分研究选择为其添加了一些中间卷积层的输出做了一个融合。
从卷积层提取特征
从卷积层提取出来的特征往往对图像中的结构化信息表述更好,因为相对于全连接层的输出往往具有一个更小的感受野,因此也更适用于instance-level retrieval,对图像的几何变化拥有更强的抗性。在实践中,我们往往选择最后一个卷积层的输出作为图像的特征表述,而且将卷积层的输出特征进行池化后,可以显著提升其鲁棒性。
特征融合策略
层级特征融合
将全连接层输出的特征(偏全局语义)与卷积层输出的特征(偏局部语义)进行融合,可以在图像语义特征表述上形成互补,并且可以在一定程度上保证检索的效率。二者的融合可以直接进行,亦或在进行融合之前,使用滑动窗口或者区域推荐网络对卷积层的输出做一个筛选。在目前的探究中,将全连接层的输出与卷积层的输出做一个融合所能取得的效果要比单纯地融合多个卷积层的特征所取得的效果要好。同时,融合2个卷积层的输出和1个全连接层的输出将会取得最好的融合效果。
对于两层特征的融合,可以采用直接拼接的策略(计算多层特征向量的加和,将求和后的结果作为融合特征),但是直接拼接的策略又有一些先天性的不足,就是在这种策略中,全局特征和局部特征对融合后特征的整体影响是一样的,导致对局部细节更加敏感的局部特征并不能在分辨两张图片两个不同物体上取得决定性的作用,也就是说高层特征的相似性会削弱低层特征的不相似性。为此,一些研究提出了一些方法来突出低层特征,例如:利用多层卷积神经网络(CNN)特征的互补优势进行图像检索。
模型级的特征融合
模型级的特征融合也可以分为模型内(intra-model)的融合和模型间(inter-model)的融合。模型内融合要求融合的两个主体网络拥有相似且相容的结构,而模型间的融合则没有这个要求。
- 模型内的融合:为防止神经网络过拟合的dropout策略,即可看做是一种模型内的特征融合,因为每个训练的epoch都会随机删除一些全连接层的神经元,删除了随机神经元后的网络即可看做是一个全新的模型,这样每个epoch即可看做是采用了一种不同模型的组合。同样,还有一些研究使用了同一网络的不同版本进行融合,例如VGG-16与VGG-19的输出特征融合以及ResNet-26和ResNet-50的融合。
- 模型间的融合:模型间的融合主要是为了融合不同模型感受野的不同。例如:有些研究中使用了一种双注意力流网络(two-stream attention network),在这个工作中,VGG-16网络用于输出语义特征,另外还有一个附加的DeepFixNet则用于生成注意力图(Attention Map,一种特征矩阵的计算方式,用以凝练有特点的矩阵数据,使卷积运算中更加关注有效特征而忽略无用特征)。
以下是几种特征融合的策略:
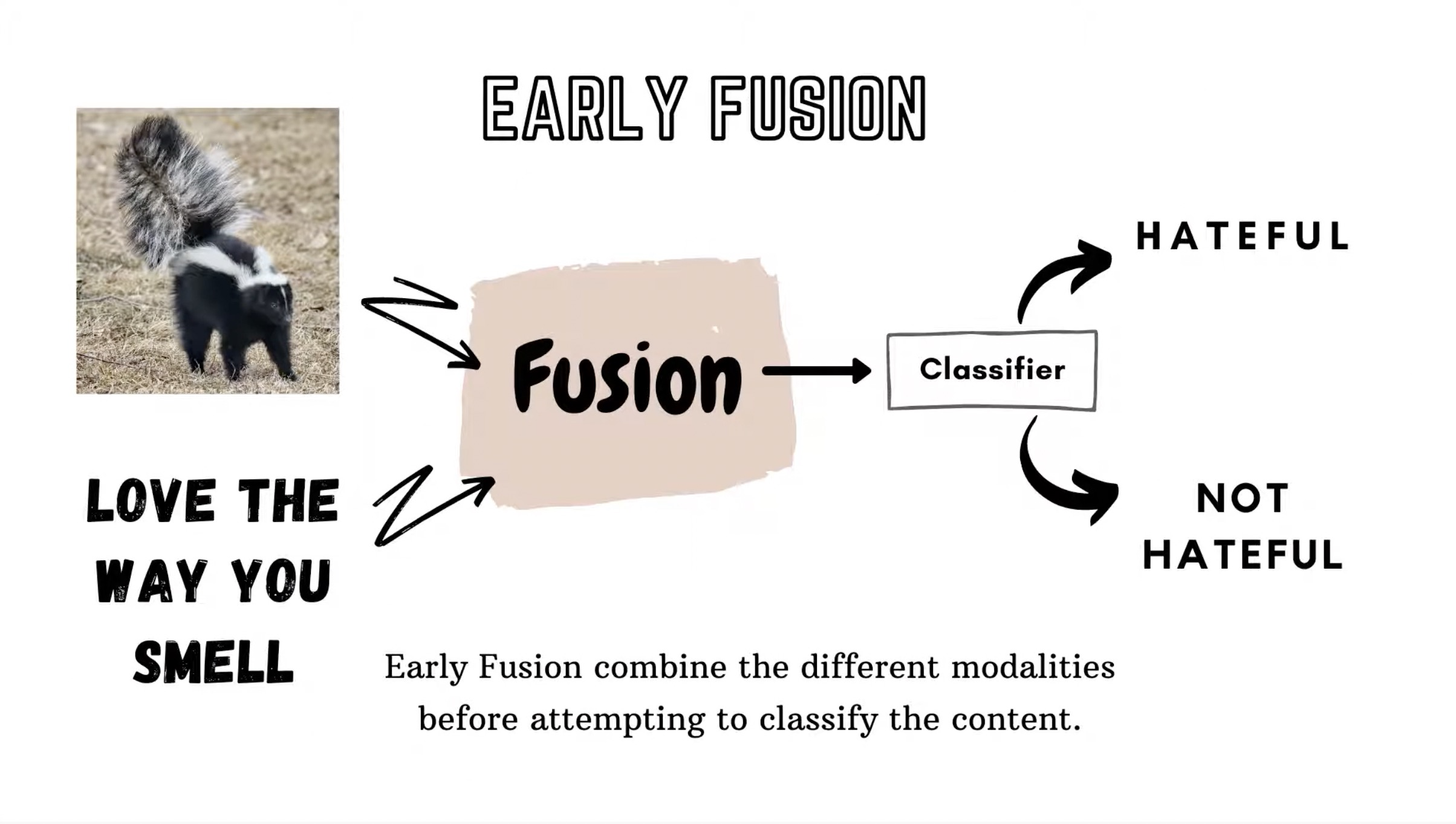
- Early Fusion:首先对原始特征进行融合,然后输入一个神经网络中进行训练,最终产生预测结果。
- Late Fusion:有2个神经网络分别产生不同的预测结果,然后再将这两个模型的结果进行fusion,以得到最终的预测结果。常见的策略有取均值、最大值、加权平均等。

深度特征增强
特征增强的本质目的还是为了提升深度特征的区分力。
特征池化
对于卷积神经网络中任意一层产生的特征图,特征聚合的方式一般就是池化,对应的有三种常见的池化策略:加和、均值以及最大池化。其中加和池化和均值池化产出的聚合特征的区分力相对较弱,因为其均等地考虑了上游特征每一个值所带来的影响,由此就弱化了那些highly activated feature所带来的影响。相反,最大池化反倒可以很好地解决这个问题,而且也更适用于稀疏的特征。同时,部分研究指出,对神经网络的最后一个卷积层的输出结果进行池化所产生的检索效果要明显好于对其它卷积层以及全连接层进行池化所产生的检索效果。
同样,还有一种特殊的池化方法——空间池化。
空间池化
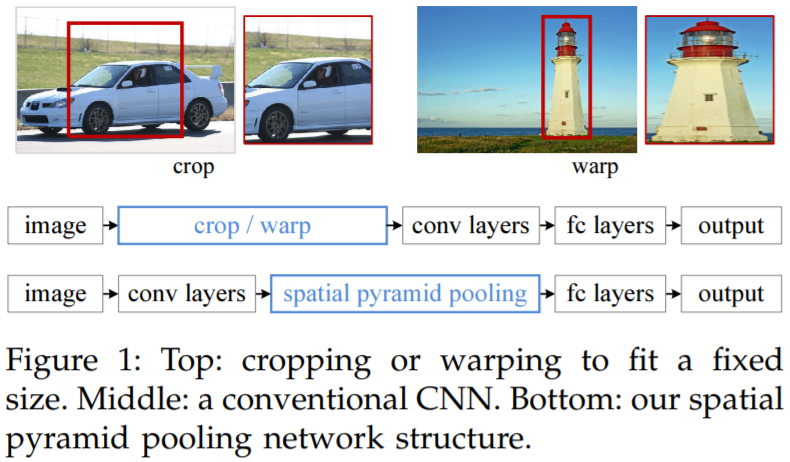
空间金字塔池化(Spatial Pyramid Pooling)的根本目的是为了使不同大小的输入特征图都能产生相同大小的输出特征。空间金字塔池化层势必要加在全连接层的前面,因为只有全连接层才需要固定尺寸的输入输出特征。
 支付宝
支付宝- 微信


