布隆过滤器
0x00 适用场景
一开始学这个布隆过滤器是为了一个分布式爬虫的项目,在这个项目中有一个需求就是判断队列中的URL是否先前已经爬取过了。如果先前已经爬取过了,那就不爬了,如果没有,那就爬取这个URL。然后就了解到了这个布隆过滤器和RedisBloom。
布隆过滤器说白了主要应用于在大量数据中判断给定数据是否存在。 这是一种基于概率的算法,什么意思呢,就是说,不存在的一定返回false,而返回true的却不一定存在。也就说它有一定的误判率。
0x01 基本原理
布隆过滤器的基本组件其实很简单,一系列的hash函数以及一个存放位序列的大表。现在我们假定一个长度为8的表,初始状态下,表中的元素均为0:
1 | +---+---+---+---+---+---+---+---+ |
现在有一组Hash函数,hash1(data)和hash2(data)。对于一个给定数据liu,我们假设hash1和hash2函数的返回值分别为为2, 4,那在这个大表中,翻置下标为2和4的元素为1,如下:
1 | +---+---+---+---+---+---+---+---+ |
对于另外一个给定数据shao,我们假设hash1和hash2函数的返回值分别为为3, 2,继续翻置,如下:
1 | +---+---+---+---+---+---+---+---+ |
当我们试图判断数据liu是否存在时,我们对这组新的数据计算那两个Hash函数,如果返回的下标在大表中所指向的字节均为1的话,那么数据存在,否则,数据不存在。
但是这样就会出现一个问题,在上面的例子中,输入数据liu和shao均翻置了下标为2的元素,这一位被2个不同的值的hash共同覆盖了。假设我们要删除数据liu然后把下标为2和4的数据重新置为0的话,那么当我们试图判断数据shao是否存在时就会返回false,显然这是错误的,因为我们并没有删除数据shao。基于此点布隆过滤器是不支持删除的。
除此之外,对于两组不相同的数据,两个hash函数可能返回相同的下标地址,假设对于输入数据liu和qun而言,两组hash函数均分别返回下标2和4,那我当插入数据liu之后,在过滤器中判断数据qun是否存在,过滤器是会返回true的,这就是误判。在Guava中,BloomFilter默认的误判率是3%,这个值在Guava中可以调的,误判率越低,这个大表就越大。这个大表的大小m和误判率fpp以及预估数据量n之间的关系为:
hash函数的个数k与表的大小m和预估数据量n之间的关系为:
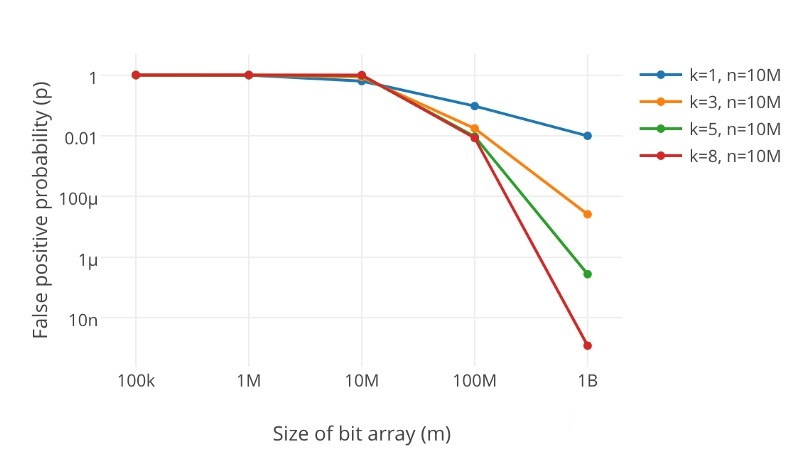
有此我们可见,误判率的大小和大表的大小m和hash函数的个数k都是呈负相关的。同时还有一幅图可以参考一下:
在Guava中,计算大表长度m和hash函数的个数k就是用的如上公式:
1 | /** |
0x02 RedisBloom的使用
0x00 基于docker的快速部署
我们可以使用docker快速部署一个RedisBloom应用:
1 | docker pull redislabs/rebloom:latest # 拉取镜像 |
0x01 控制台下使用RedisBloom
首先我们进入刚刚用docker启动的RedisBloom应用:
1 | docker exec -it redis-redisbloom redis-cli |
BF.RESERVE:创建一个新的布隆过滤器
1 | BF.RESERVE {key} {error_rate} {capacity} [EXPANSION expansion] [NONSCALING] |
必选参数:
key:新过滤器的名字error_rate:预设的错误率capacity:预计添加到布隆过滤器中的元素的个数
可选参数:
NONSCALING:如果设置了此项,当添加到布隆过滤器中的数据达到初始容量之后,不会扩容过滤器,并且超过初始设置容量的添加会抛出异常。expansion:与上一项相反,当设置了此项,布隆过滤器中存储的元素达到初始容量后会自动创建一个子过滤器,子过滤器的大小是上一个过滤器大小乘以参数expansion。
复杂度为:。
示例:
1 | 127.0.0.1:6379> BF.RESERVE newFilter 0.03 100 EXPANSION 2 |
创建一个新的布隆过滤器命名为
newFilter,预设的错误率为0.03 (3%),预计添加100个元素,超出之后自动创建子过滤器,子过滤器的大小是最后一个过滤器大小的2倍。
BF.ADD:向布隆过滤器中添加一个元素,BF.MADD:批量添加元素
1 | BF.ADD {key} {item} |
key:过滤器名item:需添加的元素
返回结果为1表示插入成功,返回结果为0表示插入的元素此前可能已经存在,也可能是发生了冲突,也就是此前添加的元素和当前添加的元素产生了相同的hash值。对于BF.MADD将会返回一个数组,数组内各数意义上同。
复杂度:,为插入的元素的个数,为hash函数的个数。
示例:
1 | 127.0.0.1:6379> BF.ADD newFilter shaoqun-liu |
BF.EXISTS:判断值是否在布隆过滤器中存在,BF.MEXISTS:批量判断
1 | BF.EXISTS {key} {item} |
key:过滤器名item:查询的元素
返回0表示元素不存在,返回1表示元素可能存在。
复杂度:,为插入的元素的个数,为hash函数的个数。
示例:
1 | 127.0.0.1:6379> BF.EXISTS newFilter shaoqun-liu |
BF.INFO:查询某布隆过滤器的详细信息
1 | BF.INFO {key} |
key:过滤器名
示例:
1 | 127.0.0.1:6379> BF.INFO newFilter |
其它命令可参考官方文档:
RedisBloom Bloom Filter Command Documentation
0x02 Java API
首先,我们可以使用Maven导入依赖:
1 | <!-- https://mvnrepository.com/artifact/com.redislabs/jrebloom --> |
我在我们的项目中,将其Client注册成了一个bean,方便日后调用,首先我们在项目的application.yml文件中配置了相关的Redis地址信息:
1 | redis: |
这几个字段都是我自定义的,如果有需要可以自己设置,然后我们创建一个Spring boot的Configuration类,导出用于操作的Client的bean,如下:
1 | package com.cstiaoji.spider.configuration; |
然后在我们的业务逻辑代码中,就可以使用如下代码进行相关的操作了:
1 | // 向名为cstiaoji-spider的布隆过滤器中添加值"www.baidu.com" |
更多信息可参考当前项目GitHub。
 支付宝
支付宝- 微信


